Yapay Sinir Ağı#
Yapay sinir ağları, karmaşık fonksiyonları yaklaşık olarak öğrenebilen bir makine öğrenmesi modelidir.
GitHub Deposu: gavinkhung/neural-network
Kitaplıkları içe aktaralım.
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from celluloid import Camera
import scienceplots
from IPython.display import Image
np.random.seed(0)
plt.style.use(["science", "no-latex"])
Eğitim Veri Kümesi#
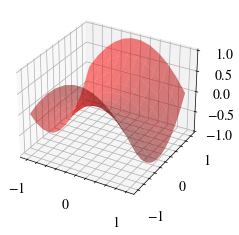
Yapay sinir ağı, bir hiperbolik paraboloidi temsil edecek parametreleri öğrenecek.
\( \begin{align*} z &= \frac{y^2}{b^2} - \frac{x^2}{a^2} \end{align*} \)
def generate_function(dims):
a = 1
b = 1
# Hyperbolic Paraboloid
x = np.linspace(-1, 1, dims)
y = np.linspace(-1, 1, dims)
X, Y = np.meshgrid(x, y)
Z = (Y**2 / b**2) - (X**2 / a**2)
X_t = X.flatten()
Y_t = Y.flatten()
Z_t = Z.flatten()
X_t = X_t.reshape((len(X_t), 1))
Y_t = Y_t.reshape((len(Y_t), 1))
Z_t = Z_t.reshape((len(Z_t), 1))
features = np.stack((X_t, Y_t), axis=1)
labels = Z_t.reshape((len(Z_t), 1, 1))
return X, Y, Z, features, labels
dims = 12
X, Y, Z, features, labels = generate_function(dims)
# Visualize the Hyperbolic Paraboloid
fig = plt.figure()
ax = fig.add_subplot(111, projection="3d")
ax.plot_surface(X, Y, Z, color="red", alpha=0.5)
<mpl_toolkits.mplot3d.art3d.Poly3DCollection at 0x10b2be3c0>
Kayıp Fonksiyonu#
Kayıp fonksiyonu, modelin performansını ölçmek ve ağırlıkları buna göre güncellemek için kullanılır. Yapay sinir ağının eğitim sürecindeki optimizasyon, kaybı en aza indiren ağırlık ve bias değerlerini bulmaya çalışır.
Ortalama Karesel Hata#
Bu örnekte olduğu gibi regresyon problemlerinde ortalama karesel hata gibi ikinci dereceden kayıp fonksiyonları sık kullanılır.
\( J = \frac{1}{n} \sum_{i=1}^{n}(y_{i}-\hat{y})^2 \)
def mse(y_true, y_pred):
return np.mean(np.power(y_true - y_pred, 2))
Ortalama Karesel Hatanın Türevi#
Ağırlıkları geri yayılım ile güncelleyebilmek için önce kayıp fonksiyonunun türevini hesaplamamız gerekir.
\( \begin{align*} J^{\prime} &= \frac{\partial}{\partial \hat{y}} [ \frac{1}{n} \sum_{i=1}^{n}(y_{i}-\hat{y})^2 ] \\ &= \frac{1}{n} \sum_{i=1}^{n}\frac{\partial}{\partial \hat{y}} [ (y_{i}-\hat{y})^2 ] \\ &= \frac{2}{n} \sum_{i=1}^{n} (y_{i}-\hat{y}) \frac{\partial}{\partial \hat{y}}[y_{i}-\hat{y}] \\ &= \frac{2}{n} \sum_{i=1}^{n} (y_{i}-\hat{y}) (-1) \\ &= \frac{2}{n} \sum_{i=1}^{n}(\hat{y}-y_{i}) \end{align*} \)
def mse_prime(y_true, y_pred):
return 2 * (y_pred - y_true) / np.size(y_true)
Yapay Sinir Ağı Katmanı#
İleri beslemeli bir yapay sinir ağı çok sayıda katmandan oluşur. Her katman, en temel haliyle, giriş verisine doğrusal bir dönüşüm uygular ve böylece çoğu zaman girişten farklı boyutta bir çıktı üretir. Ardından bu çıktıdaki her değer, aktivasyon fonksiyonu adı verilen bir fonksiyondan geçirilir.
Doğrusal cebirden hatırlayacağınız gibi, \(\mathbb{R}^n\) uzayındaki bir giriş sütun vektörü \(x\), boyutu \(m \times n\) olan bir matrisle çarpılarak \(\mathbb{R}^m\) uzayına dönüştürülebilir. Son olarak bu doğrusal dönüşüme bir bias terimi ekleyerek veriyi yukarı ya da aşağı kaydırabiliriz.
Bu nedenle her katman, doğrusal dönüşümü uygulamak için bir ağırlık matrisi ve bir bias vektörü tutar.
from abc import ABC, abstractmethod
class Layer(ABC):
def __init__(self):
self.input = None
self.output = None
self.weights = None
self.bias = None
@abstractmethod
def forward(self, input):
pass
@abstractmethod
def backward(self, output_gradient, optimizer):
pass
İleri Yayılım#
Bu süreçte giriş verisini, ileri beslemeli ağımızın tahminlerine dönüştürürüz. Girdi, ağdaki her katmandan sırayla geçirilir. Aşağıda uygulayacağımız 3 katmanlı ağın görselleştirmesi yer alıyor.

Bir katmandaki her nöron, girdilerinin ağırlıklı toplamına bir bias terimi eklenmesiyle elde edilir. Sonrasında katmandaki her nörona bir aktivasyon fonksiyonu uygulanır. Bu yapıyı göstermek için bir tam bağlantılı katman sınıfı ve ayrı bir aktivasyon fonksiyonu sınıfı tanımlayacağız.
Katmandaki her nöron için yapılan hesap, girişler ile katman ağırlıkları arasındaki çarpımların toplanıp bias teriminin eklenmesidir. Bu da, ağırlık matrisi ile giriş verisinin matris çarpımına bir bias vektörü eklenmesi olarak yazılabilir.
Dolayısıyla tam bağlantılı bir katmanın ileri yayılımı şu şekilde ifade edilir:
\( \begin{align*} Z &= W X + B \\ A &= g(Z) \end{align*} \)
Burada:
\(W\), katmanın ağırlık matrisi
\(X\), giriş verisi
\(B\), bias vektörü
\(g\), aktivasyon fonksiyonudur
Ağımızda İleri Yayılım#
3 katmanlı, tam bağlantılı bir yapay sinir ağı kuracağız ve her katmandan sonra Tanh aktivasyon fonksiyonu uygulayacağız. Bu dönüşümler şu matris çarpımlarıyla yazılabilir:
\( \begin{align*} Z_1 &= W_1 X + B_1 \\ A_1 &= tanh(Z_1) \\ \\ Z_2 &= W_2 A_1 + B_2 \\ A_2 &= tanh(Z_2) \\ \\ Z_3 &= W_3 A_2 + B_3 \\ \hat{y} &= A_3 = tanh(Z_3) \end{align*} \)
Geri Yayılım#
Geri yayılım, zincir kuralı ve gradyan inişi kullanarak yapay sinir ağındaki tüm ağırlık ve bias değerlerini güncelleme sürecidir.
Aşağıdaki denklemlerde kayıp fonksiyonu olarak \(J\) kullanılmıştır. Bu not defterinde \(J\), ortalama karesel hata kaybını temsil eder. Ortalama karesel hata tanımı için buraya bakabilirsiniz.
Amacımız, aşağıdaki denklemlerle ağırlık ve bias değerlerine gradyan inişi uygulamaktır:
\( \begin{align*} W_1 &= W_1 - lr * \frac{\partial J}{\partial W_1} \\ B_1 &= B_1 - lr * \frac{\partial J}{\partial B_1} \\ W_2 &= W_2 - lr * \frac{\partial J}{\partial W_2} \\ B_2 &= B_2 - lr * \frac{\partial J}{\partial B_2} \\ W_3 &= W_3 - lr * \frac{\partial J}{\partial W_3} \\ B_3 &= B_3 - lr * \frac{\partial J}{\partial B_3} \\ \end{align*} \)
Bunun için \(\frac{\partial J}{\partial W_1}\), \(\frac{\partial J}{\partial B_1}\), \(\frac{\partial J}{\partial W_2}\), \(\frac{\partial J}{\partial B_2}\), \(\frac{\partial J}{\partial W_3}\) ve \(\frac{\partial J}{\partial B_3}\) değerlerini zincir kuralıyla bulmamız gerekir.
Geri Yayılımda Zincir Kuralı#
Tek bir tam bağlantılı katmanın ağırlık matrisi \(W_i\) ile bias vektörü \(B_i\)’yi güncellemek için genel bir formül türetelim.
Örneğin 3. katmana gradyan inişi uygulayabilmek için, kaybın \(W_3\) ve \(B_3\) cinsinden ifadesini; yani \(\frac{\partial J}{\partial W_3}\) ve \(\frac{\partial J}{\partial B_3}\) türevlerini bulmamız gerekir.
Kayıp fonksiyonu \(J\), son katmanın çıktısı/aktivasyonu olan \(A_3\) cinsindendir. \(A_3\) ise \(Z_3\) cinsinden, \(Z_3\) de \(W_3\), \(B_3\) ve bir önceki katmanın aktivasyonu olan \(A_2\) cinsindendir. Şimdi kaybı \(W_3\) ve \(B_3\) cinsinden elde edelim.
Bu matris işlemlerini şu bileşik fonksiyonlar olarak düşünebiliriz: \(J(A_3)\), \(A_3(Z_3)\) ve \(Z_3(W_3, B_3, A_2)\)
Katman işlemlerinin ayrıntısı için buraya bakabilirsiniz.
Ağırlık Matrisi \(W\) İçin Zincir Kuralı#
Şimdi \(\frac{\partial J}{\partial W_3}\) türevini zincir kuralıyla çıkaralım.
\( \begin{align*} \frac{\partial J}{\partial W_3} &= \frac{\partial}{\partial W_3}[J(A_3(Z_3(W_3, B_3, A_2)))] \\ &= \frac{\partial J}{\partial A_3} \frac{\partial}{\partial W_3}[A_3(Z_3(W_3, B_3, A_2))] \\ &= \frac{\partial J}{\partial A_3} \frac{\partial A_3}{\partial Z_3} \frac{\partial}{\partial W_3}[Z_3(W_3, B_3, A_2))] \\ &= \frac{\partial J}{\partial A_3} \frac{\partial A_3}{\partial Z_3} \frac{\partial Z_3}{\partial W_3} \\ \end{align*} \)
Bias Vektörü \(B\) İçin Zincir Kuralı#
Şimdi de \(\frac{\partial J}{\partial B_3}\) türevini zincir kuralıyla çıkaralım.
\( \begin{align*} \frac{\partial J}{\partial B_3} &= \frac{\partial}{\partial B_3}[J(A_3(Z_3(W_3, B_3, A_2)))] \\ &= \frac{\partial J}{\partial A_3} \frac{\partial}{\partial B_3}[A_3(Z_3(W_3, B_3, A_2))] \\ &= \frac{\partial J}{\partial A_3} \frac{\partial A_3}{\partial B_3} \frac{\partial}{\partial B_3}[Z_3(W_3, B_3, A_2))] \\ &= \frac{\partial J}{\partial A_3} \frac{\partial A_3}{\partial Z_3} \frac{\partial Z_3}{\partial B_3} \\ \end{align*} \)
Ağırlık Matrisi \(W\) İçin Geri Yayılım#
\( \begin{align*} \frac{\partial J}{\partial W_3} = \frac{\partial J}{\partial A_3} \frac{\partial A_3}{\partial Z_3} \frac{\partial Z_3}{\partial W_3} \end{align*} \)
Şimdi bu ifadedeki her parçayı tek tek açalım:
\(\frac{\partial J}{\partial A_3}\), kayıp fonksiyonunun türevidir; yani ortalama karesel hatanın gradyanıdır. Türevin çıkarımı için buraya bakabilirsiniz. Genel durumda bu terim, bir sonraki katmandan (idx+1) gelen gradyandır.
\(\frac{\partial A_3}{\partial Z_3} = \frac{\partial}{\partial Z_3}[tanh(Z_3)]\), aktivasyon fonksiyonunun türevidir. Türevin çıkarımı için buraya bakabilirsiniz.
\(\frac{\partial Z_3}{\partial W_3} = \frac{\partial}{\partial W_3}[W_3 A_2 + B_3] = A_2\), katmana giren asıl veridir; yani bir önceki katmanın (idx-1) çıktısıdır.
Dolayısıyla tam bağlantılı bir katmandaki ağırlık matrisinin gradyanı şu üç bileşenin matris çarpımıyla elde edilir:
Bir sonraki katmandan (idx+1) gelen gradyan
Aktivasyon fonksiyonunun türevi
Bir önceki katmandan (idx-1) gelen girdi
Bias Vektörü \(B\) İçin Geri Yayılım#
\( \begin{align*} \frac{\partial J}{\partial B_3} = \frac{\partial J}{\partial A_3} \frac{\partial A_3}{\partial Z_3} \frac{\partial Z_3}{\partial B_3} \end{align*} \)
Buradaki parçaları da tek tek inceleyelim:
\(\frac{\partial J}{\partial A_3}\), kayıp fonksiyonunun türevidir; yani ortalama karesel hatanın gradyanıdır. Ayrıntılı türetim için buraya bakabilirsiniz. Genel durumda bu terim, bir sonraki katmandan (idx+1) gelen gradyandır.
\(\frac{\partial A_3}{\partial Z_3}\), aktivasyon fonksiyonunun türevidir. Ayrıntılı türetim için buraya bakabilirsiniz.
\(\frac{\partial Z_3}{\partial B_3} = \frac{\partial}{\partial B_3}[W_3 A_2 + B_3] = 1\) olduğundan, bu terimi gradyan hesabında ayrıca dikkate almamıza gerek yoktur.
Sonuç olarak tam bağlantılı bir katmandaki bias vektörünün gradyanı şu iki bileşenin çarpımıyla elde edilir:
Bir sonraki katmandan (idx+1) gelen gradyan
Aktivasyon fonksiyonunun türevi
Konuyu derinleştirmek isterseniz şu kaynaklara da bakabilirsiniz:
Neural Network from Scratch. Bu not defterini yazarken ben de bu videodan yararlandım.
Tam Bağlantılı Katmanlar#
Dense layer, yani tam bağlantılı katman, her nöronun bir önceki katmandaki tüm nöronlara bağlı olduğu katmandır. Yukarıda ileri ve geri yayılım için türettiğimiz denklemleri kullanarak katman sınıfımızın forward() ve backward() metotlarını yazalım.
class Dense(Layer):
def __init__(self, input_neurons, output_neurons):
# Random Values from Normal Distribution
# self.weights = np.random.randn(output_neurons, input_neurons)
# self.bias = np.random.randn(output_neurons, 1)
# All Zeros
# self.weights = np.zeros((output_neurons, input_neurons))
# self.bias = np.zeros((output_neurons, 1))
# Xavier Initialization Uniform Distribution
limit = np.sqrt(6 / (input_neurons + output_neurons))
self.weights = np.random.uniform(
-limit, limit, size=(output_neurons, input_neurons)
)
self.bias = np.zeros((output_neurons, 1))
def forward(self, input):
self.input = input
return np.matmul(self.weights, self.input) + self.bias
def backward(self, output_gradient, optimizer):
# Calculate gradients
weights_gradient = np.matmul(output_gradient, self.input.T)
input_gradient = np.dot(self.weights.T, output_gradient)
# Update weights and biases
self.weights, self.bias = optimizer.backward(
self.weights, weights_gradient, self.bias, output_gradient
)
return input_gradient
Aktivasyon Fonksiyonu#
Aktivasyon fonksiyonları, matris çarpımından sonra uygulanarak yapay sinir ağlarına doğrusal olmayan davranış kazandırır. Doğru aktivasyon fonksiyonunu seçmek, ağın eğitim verisindeki genel örüntüleri öğrenebilmesi açısından kritiktir. Özellikle ReLU, 2012 tarihli AlexNet çalışmasında da görüldüğü gibi, çok katmanlı derin ağların eğitiminde oldukça etkilidir; çünkü gradyanların neredeyse sıfıra inmesiyle ağın ağırlıklarını güncelleyememesi anlamına gelen kaybolan gradyan sorununu azaltmaya yardımcı olur.
class Activation(Layer):
def __init__(self, activation, activation_prime):
self.activation = activation
self.activation_prime = activation_prime
def forward(self, input_val):
self.input = input_val
return self.activation(self.input)
def backward(self, output_gradient, optimizer):
return np.multiply(output_gradient, self.activation_prime(self.input))
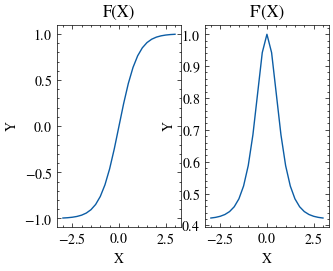
def plot(self, x_min, x_max, points=25):
x = np.linspace(x_min, x_max, points)
y = self.activation(x)
y_prime = self.activation_prime(y)
fig, axes = plt.subplots(1, 2)
axes[0].plot(x, y)
axes[0].set_xlabel("X")
axes[0].set_ylabel("Y")
axes[0].set_title("F(X)")
axes[1].plot(x, y_prime)
axes[1].set_xlabel("X")
axes[1].set_ylabel("Y")
axes[1].set_title("F'(X)")
Tanh Aktivasyon Fonksiyonu#
Ağımızda Tanh aktivasyon fonksiyonunu kullanacağız:
\( \begin{align*} \sigma(z) &= \frac{e^z-e^{-z}}{e^z+e^{-z}} \end{align*} \)
Tanh Aktivasyon Fonksiyonunun Türevi#
Gradyan inişi, aktivasyon fonksiyonunun türevini bilmeye dayandığı için şimdi Tanh fonksiyonunun türevini çıkaralım.
\( \begin{align*} \sigma^\prime(z) &= \frac{\partial}{\partial z} [ \frac{e^z-e^{-z}}{e^z+e^{-z}} ] \\ &= \frac{(e^z+e^{-z})\frac{\partial}{\partial z}[e^z-e^{-z}] - (e^z-e^{-z})\frac{\partial}{\partial z}[e^z+e^{-z}]}{({e^z+e^{-z}})^2} \\ &= \frac{(e^z+e^{-z})(e^z+e^{-z}) - (e^z-e^{-z})(e^z-e^{-z})}{({e^z+e^{-z}})^2} \\ &= \frac{(e^z+e^{-z})^2 - (e^z-e^{-z})^2}{({e^z+e^{-z}})^2} \\ &= \frac{(e^z+e^{-z})^2}{({e^z+e^{-z}})^2} - \frac{(e^z-e^{-z})^2}{({e^z+e^{-z}})^2} \\ &= 1 - [\sigma(z)]^2 \end{align*} \)
Tanh fonksiyonunun türevini elde ettiğimize göre, şimdi Tanh aktivasyon fonksiyonunu temsil eden sınıfı yazalım.
class Tanh(Activation):
def __init__(self):
tanh = lambda x: np.tanh(x)
tanh_prime = lambda x: 1 - np.tanh(x) ** 2
super().__init__(tanh, tanh_prime)
Tanh().plot(-3, 3)
Optimizasyon Algoritması#
Parametrelerin bir sonraki adımda nasıl güncelleneceğini belirlemek için optimizasyon algoritması olarak gradyan inişini kullanacağız.
\( X_{n+1} = X_n - lr * \frac{\partial}{\partial X} f(X_n)\).
Şimdi bu denklemi kullanarak ağırlık matrisini ve bias vektörünü güncelleyen bir sınıf oluşturalım.
class GradientDescentOptimizier:
def __init__(self, learning_rate):
self.learning_rate = learning_rate
def backward(self, weights, weights_gradient, bias, output_gradient):
weights -= self.learning_rate * weights_gradient
bias -= self.learning_rate * output_gradient
return weights, bias
Grafik Fonksiyonları#
Bu not defteri, ağın eğitim süreci boyunca pek çok farklı görselleştirme üretecek.
create_scatter_and_3d_plot(), solda ortalama karesel hata grafiği, sağda ise 3B grafik olacak şekilde iki sütunlu bir görünüm oluşturur.
create_3d_and_3d_plot(), iki adet 3B grafikten oluşan iki sütunlu bir görünüm oluşturur.
plot_3d_predictions(), ağın o andaki tahminlerini ve beklenen çıktıyı 3B olarak çizer.
plot_layer_loss_landscape(), bir katmanın mevcut ağırlıklarının en uygun ağırlıklara ne kadar yakın olduğunu, ağırlıklar biraz kaydırıldığında toplam ortalama karesel hatanın nasıl değiştiğine bakarak gösterir.
import copy
def create_scatter_and_3d_plot():
fig, ax = plt.subplots(1, 3, figsize=(16 / 9.0 * 4, 4 * 1))
fig.suptitle("Yapay Sinir Ağı Tahminleri")
ax[0].set_xlabel("Epok", fontweight="normal")
ax[0].set_ylabel("Hata", fontweight="normal")
ax[0].set_title("Ortalama Karesel Hata")
ax[1].axis("off")
ax[2].axis("off")
ax[2] = fig.add_subplot(1, 2, 2, projection="3d")
ax[2].set_xlabel("X")
ax[2].set_ylabel("Y")
ax[2].set_zlabel("Z")
ax[2].set_title("Fonksiyon Yaklaştırma")
ax[2].view_init(20, -35)
ax[2].set_zlim(-1, 1)
ax[2].axis("equal")
camera = Camera(fig)
return ax[0], ax[2], camera
def create_3d_and_3d_plot():
fig, ax = plt.subplots(
1, 2, figsize=(16 / 9.0 * 4, 4 * 1), subplot_kw={"projection": "3d"}
)
fig.suptitle("Yapay Sinir Ağı Kayıp Yüzeyi")
ax[0].set_xlabel("W3_1")
ax[0].set_ylabel("W3_2")
ax[0].set_zlabel("MSE")
ax[0].set_title("Ortalama Karesel Hata")
ax[0].view_init(20, -35)
ax[0].set_zlim(-1, 1)
ax[0].axis("equal")
ax[1].set_xlabel("X")
ax[1].set_ylabel("Y")
ax[1].set_zlabel("Z")
ax[1].set_title("Fonksiyon Yaklaştırma")
ax[1].view_init(20, -35)
ax[1].set_zlim(-1, 1)
ax[1].axis("equal")
camera = Camera(fig)
return ax[0], ax[1], camera
def plot_3d_predictions(ax, X, Y, Z, predictions, dims):
# Plot Neural Network Fonksiyon Yaklaştırma
# Ground truth
ground_truth_legend = ax.plot_surface(
X, Y, Z, color="red", alpha=0.5, label="Gerçek Etiket"
)
# Yapay Sinir Ağı Tahminleri
predictions_legend = ax.scatter(
X,
Y,
predictions.reshape((dims, dims)),
color="blue",
alpha=0.2,
label="Tahmin",
)
ax.plot_surface(
X,
Y,
predictions.reshape((dims, dims)),
color="blue",
alpha=0.3,
)
ax.legend(
(ground_truth_legend, predictions_legend),
("Gerçek Etiket", "Tahminler"),
loc="upper left",
)
def plot_layer_loss_landscape(
ax0,
network,
target_layer_idx,
features,
labels,
w1_min,
w1_max,
w2_min,
w2_max,
loss_dims,
):
# current target layer weights
target_layer_idx = target_layer_idx % len(network)
w1 = network[target_layer_idx].weights[0][0]
w2 = network[target_layer_idx].weights[0][1]
curr_error = 0
for x, y in zip(features, labels):
output = x
for layer in network:
output = layer.forward(output)
curr_error += mse(y, output)
curr_error /= labels.size
ax0.scatter([w1], [w2], [curr_error], color="red", alpha=0.4)
target_layer = copy.deepcopy(network[target_layer_idx])
w1_range = np.linspace(w1_min, w1_max, loss_dims)
w2_range = np.linspace(w2_min, w2_max, loss_dims)
w1_range, w2_range = np.meshgrid(w1_range, w2_range)
w_range = np.stack((w1_range.flatten(), w2_range.flatten()), axis=1)
error_range = np.array([])
for target_layer_weight in w_range:
target_layer_weight = target_layer_weight.reshape(1, 2)
target_layer.weights[0, :2] = target_layer_weight[0, :2]
error = 0
for x, y in zip(features, labels):
output = x
for layer_idx, layer in enumerate(network):
if layer_idx == target_layer_idx:
output = target_layer.forward(output)
else:
output = layer.forward(output)
error += mse(y, output)
error /= labels.size
error_range = np.append(error_range, error)
ax0.plot_surface(
w1_range,
w2_range,
error_range.reshape(loss_dims, loss_dims),
color="blue",
alpha=0.1,
)
def plot_mse_and_predictions(
ax0, ax1, idx, visible_mse, mse_idx, errors, X, Y, Z, predictions, dims
):
ax0.plot(
mse_idx[visible_mse][: idx + 1],
errors[visible_mse][: idx + 1],
color="red",
alpha=0.5,
)
plot_3d_predictions(ax1, X, Y, Z, predictions, dims)
def plot_loss_landscape_and_predictions(
ax0,
ax1,
network,
target_layer_idx,
features,
labels,
X,
Y,
Z,
predictions,
preds_dims,
w1_min=-5,
w1_max=5,
w2_min=-5,
w2_max=5,
loss_dims=20,
):
plot_3d_predictions(ax1, X, Y, Z, predictions, preds_dims)
plot_layer_loss_landscape(
ax0,
network,
target_layer_idx,
features,
labels,
w1_min,
w1_max,
w2_min,
w2_max,
loss_dims,
)
def show_epoch(epoch):
return (
epoch < 25
or (epoch < 25 and epoch % 2 == 0)
or (epoch <= 100 and epoch % 10 == 0)
or (epoch <= 500 and epoch % 25 == 0)
or (epoch <= 1000 and epoch % 50 == 0)
or epoch % 250 == 0
)
Modeli Eğitmek#
Şimdi her şeyi bir araya getirip yapay sinir ağını eğitelim. Her epokta şu adımları uygulayacağız:
Modelin tahminlerini almak için eğitim verisini ağa vereceğiz
Tahminlerle beklenen değer arasındaki kaybı hesaplayacağız
Kaybı kullanarak optimizer ile ağırlık ve bias değerlerini güncelleyeceğiz
Eğitim sürecini görselleştirmek için çizim fonksiyonlarını çağıracağız
def fit(
network,
features,
labels,
X,
Y,
Z,
preds_dims,
epochs,
optimizer,
mse_plot_filename,
loss_landscape_plot_filename,
):
mse_idx = np.arange(1, epochs + 1)
errors = np.full(epochs, -1)
mse_ax, predictions_ax1, camera1 = create_scatter_and_3d_plot()
loss_landscape_ax, predictions_ax2, camera2 = create_3d_and_3d_plot()
network_len = len(network)
for idx in range(epochs):
error = 0
predictions = np.array([])
for x, y in zip(features, labels):
# Forward Propagation
output = x
for layer in network:
output = layer.forward(output)
predictions = np.append(predictions, output)
# Store Hata
# no need to convert to numpy cpu, since both are tensors on device
error += mse(y, output)
# Backpropagation
grad = mse_prime(y, output)
for layer in reversed(network):
grad = layer.backward(grad, optimizer)
error /= len(X)
if show_epoch(idx):
print(f"epok: {idx}, MSE: {error}")
# Plot MSE
errors[idx] = error
visible_mse = errors != -1
plot_mse_and_predictions(
mse_ax,
predictions_ax1,
idx,
visible_mse,
mse_idx,
errors,
X,
Y,
Z,
predictions,
preds_dims,
)
# plot the loss landscape of the second to last layer
# a 3D plot can be made because it's only 2 neurons
plot_loss_landscape_and_predictions(
loss_landscape_ax,
predictions_ax2,
network,
-2,
features,
labels,
X,
Y,
Z,
predictions,
preds_dims,
)
camera1.snap()
camera2.snap()
animation1 = camera1.animate()
animation1.save(mse_plot_filename, writer="pillow")
animation2 = camera2.animate()
animation2.save(loss_landscape_plot_filename, writer="pillow")
plt.show()
Model aşağıdaki şekilde görselleştirilebilir:
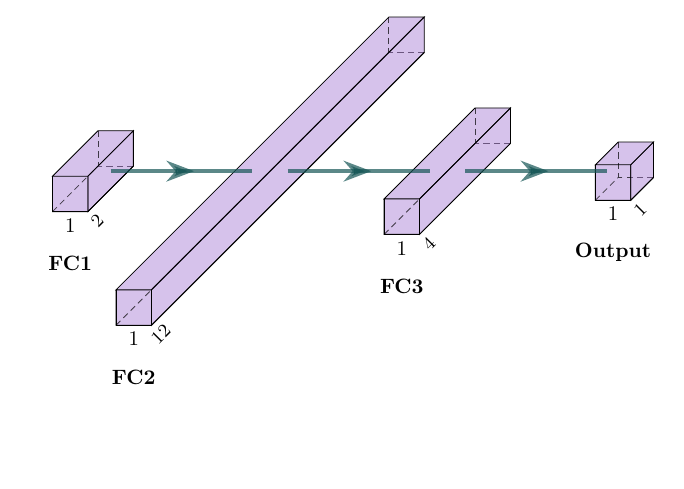
Modelimiz, her katmandan sonra Tanh() aktivasyon fonksiyonu bulunan 3 katmandan oluşuyor.
Katman 1:
Giriş Boyutu: 2
Çıkış Boyutu: 12
Katman 2:
Giriş Boyutu: 12
Çıkış Boyutu: 2
Katman 3:
Giriş Boyutu: 2
Çıkış Boyutu: 1
model = [Dense(2, 12), Tanh(), Dense(12, 2), Tanh(), Dense(2, 1), Tanh()]
Modelimizi eğitmek için modelimizi ve optimizer’ı eğitim fonksiyonumuza verelim.
epochs = 301
learning_rate = 0.005
optimizer = GradientDescentOptimizier(learning_rate)
mse_plot_filename = "neural_network.gif"
loss_landscape_plot_filename = "neural_network_loss_landscape.gif"
fit(
model,
features,
labels,
X,
Y,
Z,
dims,
epochs,
optimizer,
mse_plot_filename,
loss_landscape_plot_filename,
)
epok: 0, MSE: 3.0033681391919607
epok: 1, MSE: 2.861607692334731
epok: 2, MSE: 2.825853287737221
epok: 3, MSE: 2.817140865761648
epok: 4, MSE: 2.814117393067352
epok: 5, MSE: 2.809973710893726
epok: 6, MSE: 2.802345213761619
epok: 7, MSE: 2.790241710322016
epok: 8, MSE: 2.7730636908227755
epok: 9, MSE: 2.7502645093729328
epok: 10, MSE: 2.721249705555071
epok: 11, MSE: 2.685389899197139
epok: 12, MSE: 2.642101512218608
epok: 13, MSE: 2.5909672804676966
epok: 14, MSE: 2.5318693918216923
epok: 15, MSE: 2.4651083530357476
epok: 16, MSE: 2.3914851384273637
epok: 17, MSE: 2.3123291935128214
epok: 18, MSE: 2.229456375261004
epok: 19, MSE: 2.1450438173269872
epok: 20, MSE: 2.061423945351906
epok: 21, MSE: 1.9808288922004154
epok: 22, MSE: 1.9051432156154489
epok: 23, MSE: 1.8357262341875262
epok: 24, MSE: 1.7733404220039113
epok: 25, MSE: 1.7181844787747815
epok: 30, MSE: 1.5333665989875447
epok: 40, MSE: 1.3570304555393908
epok: 50, MSE: 1.2049292538302123
epok: 60, MSE: 1.0420867215852365
epok: 70, MSE: 0.8858079903889658
epok: 75, MSE: 0.8162489390669961
epok: 80, MSE: 0.754296517010142
epok: 90, MSE: 0.6530217909549154
epok: 100, MSE: 0.5740174523365328
epok: 125, MSE: 0.3793356171105369
epok: 150, MSE: 0.24891189943713607
epok: 175, MSE: 0.22012182602057564
epok: 200, MSE: 0.20367177160551206
epok: 225, MSE: 0.1908399435300109
epok: 250, MSE: 0.1800010056452712
epok: 275, MSE: 0.17054412799607377
epok: 300, MSE: 0.16213374967702016
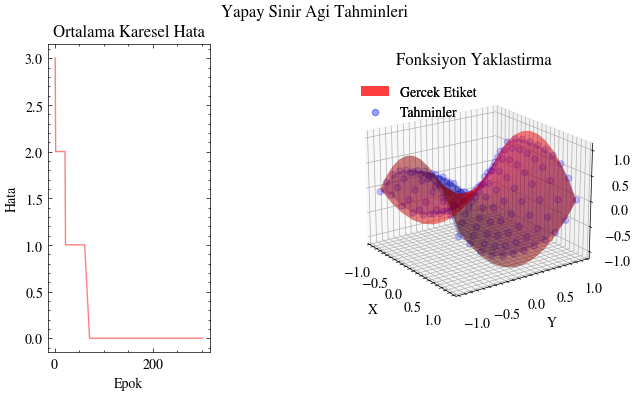
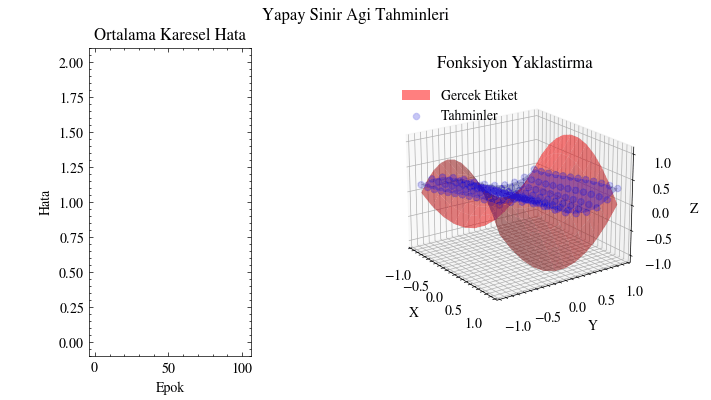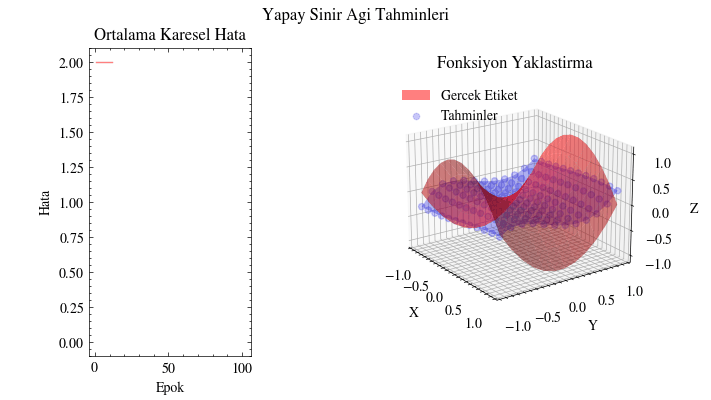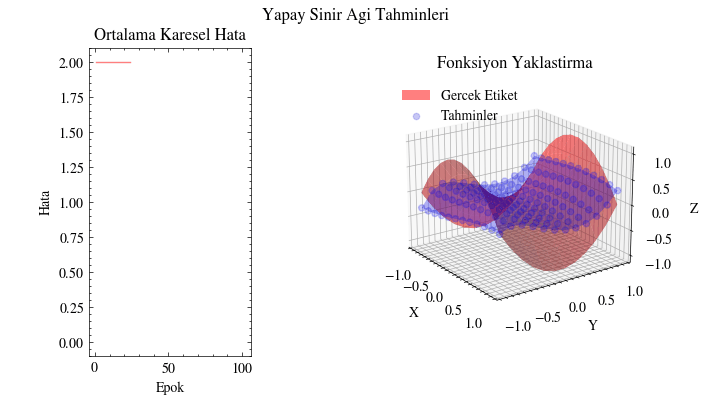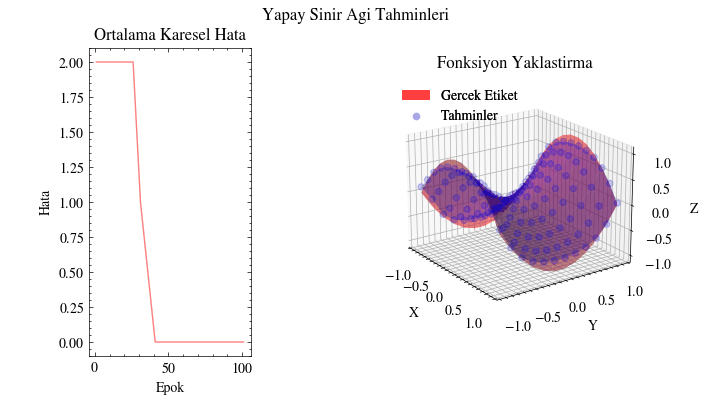
Çıktı Animasyonu#
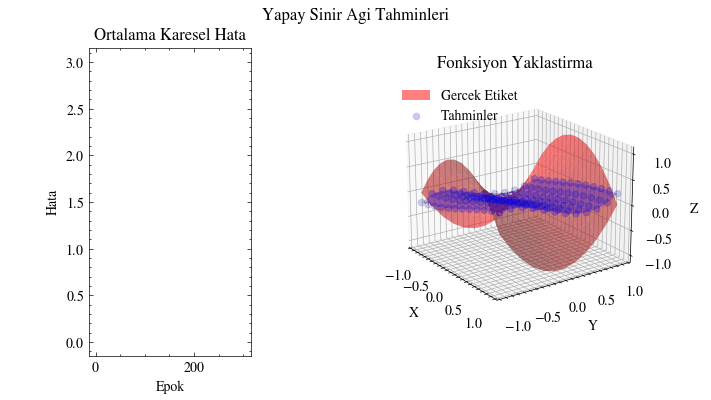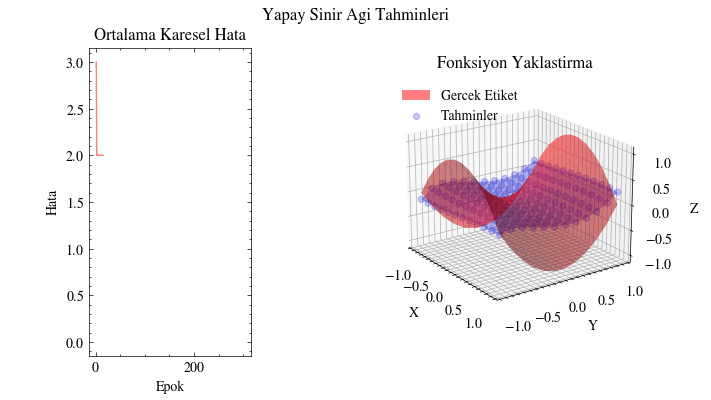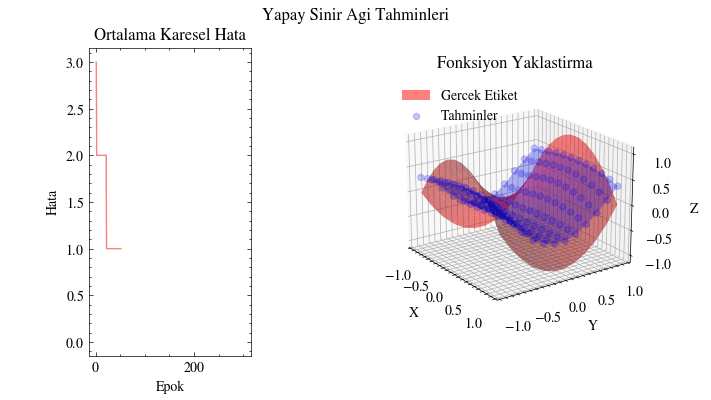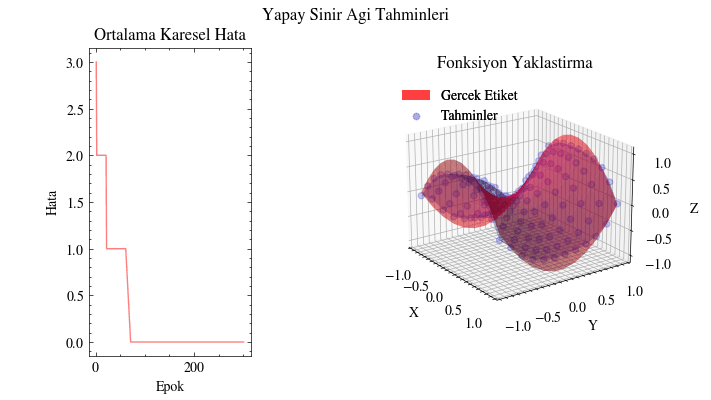
Bu görselleştirmede tahminlerin gerçek yüzeyi giderek yakaladığını görüyoruz. Yapay sinir ağı, bu fonksiyona uyacak uygun parametreleri bulabiliyor. Bunun uygulama alanlarını düşünün: örneğin insanların alışveriş alışkanlıklarına dair girdilerden onlara ne önerilebileceğini tahmin edebiliriz. Bir sosyal medya gönderisinin ya da sıradaki dizinin önerilip önerilmeyeceğini benzer şekilde modelleyebiliriz. Kısacası sinir ağları, verinin içindeki örüntüleri ortaya çıkarıp anlamlı ilişkiler öğrenebilir.
Image(filename=mse_plot_filename)
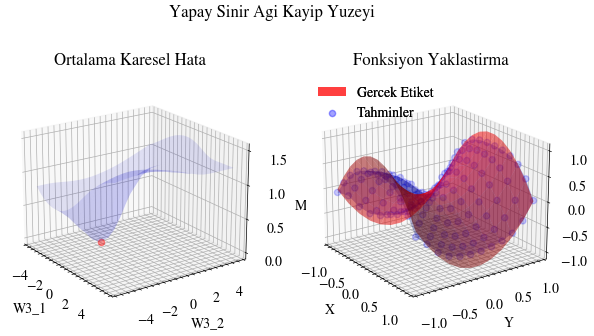
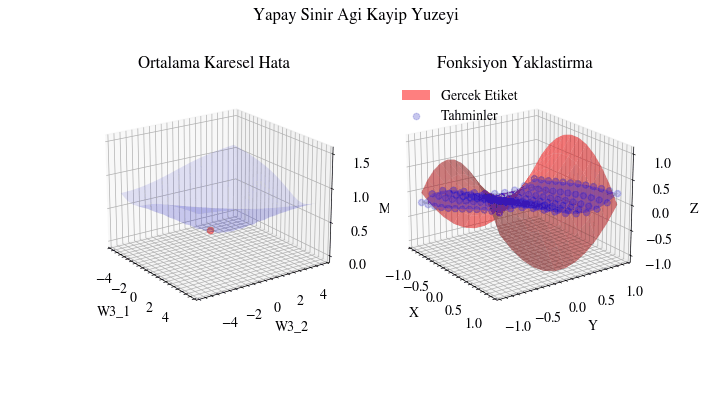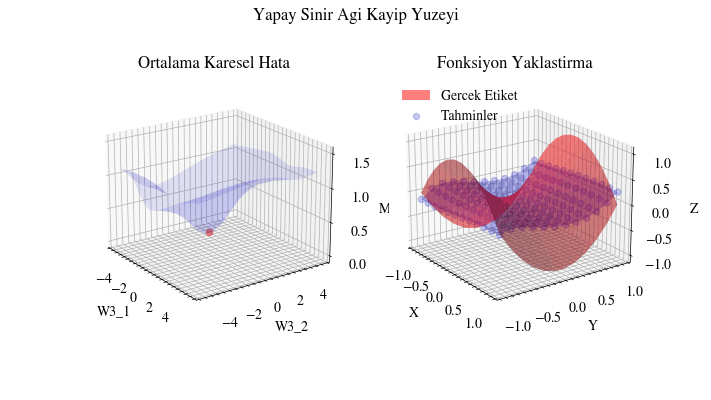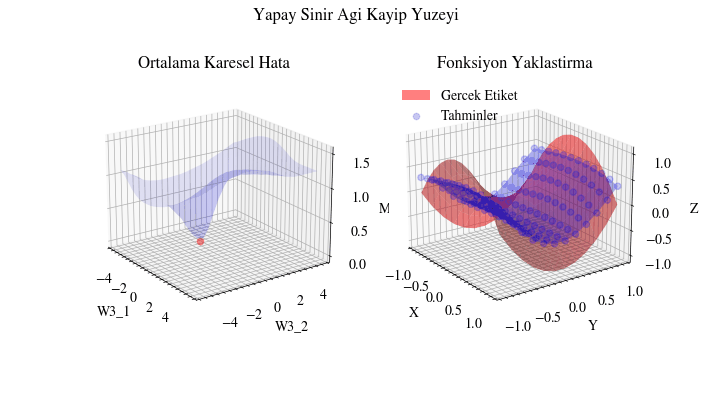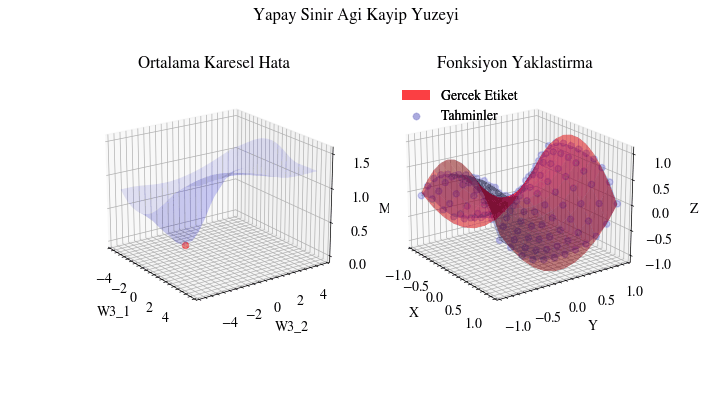
Aşağıdaki görselleştirme, geri yayılımın yapay sinir ağı için en uygun ağırlıkları bulduğunu gösteriyor. Soldaki grafikte kırmızı nokta, ağın son katmanındaki ağırlık matrisinin mevcut değerini temsil ediyor. Z ekseni ortalama karesel hata kaybını gösteriyor. Eğer ağırlıklar şu anki değerlerinde olmasaydı, kayıp minimum noktada olmazdı. Başka bir deyişle geri yayılım gerçekten de ağırlıkları en uygun (yerel ekstremum) değere doğru taşıyor ve ağın yakınsamasını sağlıyor.
Image(filename=loss_landscape_plot_filename)
PyTorch ile Uygulama#
PyTorch gibi makine öğrenmesi kütüphaneleri, yapay sinir ağlarını farklı türde optimize donanımlar üzerinde kolayca eğitip test etmek için hazır araçlar sunar. Şimdi aynı ağı PyTorch ile kuralım.
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(0)
<torch._C.Generator at 0x1152f6af0>
PyTorch nn.Module#
Yapay sinir ağımızı, PyTorch’taki nn.Module sınıfından türeyen bir alt sınıf oluşturarak tanımlarız. Bu sınıf, ağdaki tüm katmanları ve verinin ağ içinde nasıl aktığını belirtir. forward() metodu, ileri yayılımın kendisidir. Dikkat ederseniz geri yayılım için ayrıca bir şey tanımlamamız gerekmiyor; PyTorch bunu otomatik türev alma desteğiyle bizim yerimize yapıyor. Tek yapmamız gereken, PyTorch’un sağladığı bir optimizer sınıfını içe aktarıp model parametrelerini ona vermek. Makine öğrenmesi kütüphanelerinin güzelliği de tam olarak burada.
class TorchNet(nn.Module):
def __init__(self):
super(TorchNet, self).__init__()
# define the layers
self.fc1 = nn.Linear(2, 14)
self.fc2 = nn.Linear(14, 2)
self.fc3 = nn.Linear(2, 1)
def forward(self, x):
# pass the result of the previous layer to the next layer
x = F.tanh(self.fc1(x))
x = F.tanh(self.fc2(x))
return F.tanh(self.fc3(x))
PyTorch ile Eğitim#
Kendi uygulamamızdaki gibi, şimdi eğitim sürecini modelimiz üzerinden tanımlayalım. Her epokta şu adımları uygulayacağız:
Modelin tahminlerini almak için eğitim verisini ağa vereceğiz
Tahminlerle beklenen değer arasındaki kaybı hesaplayacağız
Kaybı kullanarak optimizer ile ağırlık ve bias değerlerini güncelleyeceğiz
Eğitim sürecini görselleştirmek için çizim fonksiyonlarını çağıracağız
def torch_fit(
model, features, labels, X, Y, Z, dims, epochs, optimizer, output_filename
):
mse_idx = np.arange(1, epochs + 1)
errors = np.full(epochs, -1)
mse_ax, predictions_ax1, camera1 = create_scatter_and_3d_plot()
loss_fn = nn.MSELoss()
for idx in range(epochs):
error = 0
predictions = np.array([])
for x, y in zip(features, labels):
# Forward Propagation
output = model(x)
output_np = output.detach().cpu().numpy()
predictions = np.append(predictions, output_np)
# Store Hata
loss = loss_fn(output, y)
error += loss.detach().cpu().numpy()
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
error /= len(X)
if show_epoch(idx):
print(f"epok: {idx}, MSE: {error}")
# Plot MSE
errors[idx] = error
visible_mse = errors != -1
plot_mse_and_predictions(
mse_ax,
predictions_ax1,
idx,
visible_mse,
mse_idx,
errors,
X,
Y,
Z,
predictions,
dims,
)
camera1.snap()
animation1 = camera1.animate()
animation1.save(output_filename, writer="pillow")
plt.show()
Eğitim fonksiyonunu çağırıp modele eğitim verisini ve optimizer’ı verelim.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch_model = TorchNet().to(device)
# the inputs and outputs for PyTorch must be tensors
features_tensor = torch.tensor(features, device=device, dtype=torch.float32).squeeze(-1)
labels_tensor = torch.tensor(labels, device=device, dtype=torch.float32).squeeze(-1)
epochs = 101
learning_rate = 0.005
optimizer = torch.optim.SGD(torch_model.parameters(), lr=learning_rate, momentum=0.0)
output_filename_pytorch = "neural_network_pytorch.gif"
torch_fit(
torch_model,
features_tensor,
labels_tensor,
X,
Y,
Z,
dims,
epochs,
optimizer,
output_filename_pytorch,
)
epok: 0, MSE: 2.984565496444702
epok: 1, MSE: 2.7075679302215576
epok: 2, MSE: 2.6843481063842773
epok: 3, MSE: 2.6776468753814697
epok: 4, MSE: 2.681764841079712
epok: 5, MSE: 2.690561294555664
epok: 6, MSE: 2.700050115585327
epok: 7, MSE: 2.7078511714935303
epok: 8, MSE: 2.7127304077148438
epok: 9, MSE: 2.7142040729522705
epok: 10, MSE: 2.7122199535369873
epok: 11, MSE: 2.706908941268921
epok: 12, MSE: 2.6984355449676514
epok: 13, MSE: 2.686903715133667
epok: 14, MSE: 2.672307014465332
epok: 15, MSE: 2.654496908187866
epok: 16, MSE: 2.633166790008545
epok: 17, MSE: 2.607834815979004
epok: 18, MSE: 2.5778286457061768
epok: 19, MSE: 2.542280435562134
epok: 20, MSE: 2.500131845474243
epok: 21, MSE: 2.4501829147338867
epok: 22, MSE: 2.3912041187286377
epok: 23, MSE: 2.3221094608306885
epok: 24, MSE: 2.2422282695770264
epok: 25, MSE: 2.1515371799468994
epok: 30, MSE: 1.5780067443847656
epok: 40, MSE: 0.4502730071544647
epok: 50, MSE: 0.15558338165283203
epok: 60, MSE: 0.1038421019911766
epok: 70, MSE: 0.08925560116767883
epok: 75, MSE: 0.08637460321187973
epok: 80, MSE: 0.08450803905725479
epok: 90, MSE: 0.08177543431520462
epok: 100, MSE: 0.0793890729546547
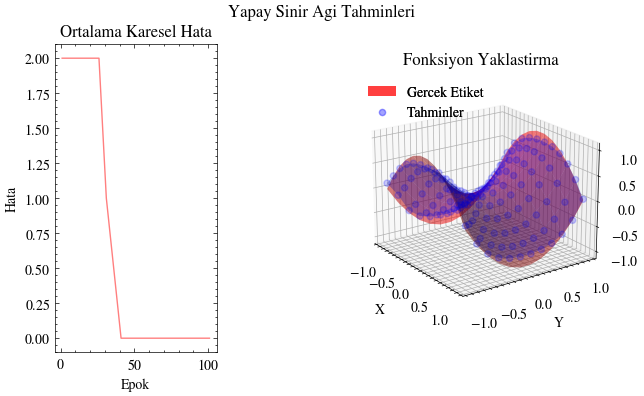
Image(filename=output_filename_pytorch)