Gradyan İnişi#
Gradyan inişi, bir fonksiyonun yerel minimum ya da maksimum noktalarını bulmaya yarayan bir optimizasyon algoritmasıdır. Makine öğrenmesinde bunun önemi şudur: modelimizin kayıp fonksiyonunu en aza indiren parametreleri bulmak isteriz. Kayıp fonksiyonu, modelin tahminleriyle gerçek değerler arasındaki hatayı ölçer. Bu not defterinde doğrusal regresyonu gradyan inişiyle eğiterek en uygun eğimi ve y-kesişimini bulacağız.
Eğitim Veri Kümesi#
Kitaplıkları içe aktaralım.
import numpy as np
import matplotlib.pyplot as plt
import scienceplots
from IPython.display import display, Latex, Image
from celluloid import Camera
np.random.seed(0)
plt.style.use(["science", "no-latex"])
Şimdi eğitim veri kümesini inceleyelim. txt dosyasının 2. ve 4. sütunlarını kullanacağız. Doğrusal regresyon modeli, veriye en iyi uyan eğim ve y-kesişim değerlerini bulacak.
fname = "REGRESSION-gradientDescent-data.txt"
x, y = np.loadtxt(fname, delimiter=",", unpack=True, skiprows=1, usecols=(2, 4))
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(x, y, color="#1f77b4", marker="o", alpha=0.25)
<matplotlib.collections.PathCollection at 0x10e94b680>
Kayıp Fonksiyonu: Ortalama Karesel Hata#
Doğrusal regresyon modelinde tahmin edilen değer \(\hat{y}\), ağırlık ile giriş değerinin çarpımına sabit terimin eklenmesiyle elde edilir.
\(\hat{y} = w x + b\)
Bu not defterinde kayıp fonksiyonu olarak ortalama karesel hatayı kullanacağız.
\( \begin{align*} MSE &= \frac{1}{n} \sum_{i=1}^{n}(y_{i}-\hat{y})^2 \\ &= \frac{1}{n} \sum_{i=1}^{n}(y_{i}-(w x_{i} + b))^2 \end{align*} \)
Kayıp Fonksiyonunun Gradyanı#
def mse_loss(x, y, w, b):
return np.mean(np.square(y - (w * x + b)))
Gradyan inişinde her epokta bir parametre, fonksiyonun gradyanı ile öğrenme oranının (\(lr\)) çarpımı kadar azaltılarak güncellenir. Öğrenme oranı, parametrelerin ne kadar değişeceğini belirler. Küçük öğrenme oranları daha hassas ama daha yavaştır; büyük öğrenme oranları ise daha hızlıdır, ancak modelin yerel ekstremumlara ulaşmasını zorlaştırabilir.
\( \begin{align*} X_{n+1} = X_n - lr * \frac{\partial}{\partial X} f(X_n) \end{align*} \)
Doğrusal regresyon modelimiz için en uygun eğimi (\(w\)) ve y-kesişimini (\(b\)) aradığımızdan, kayıp fonksiyonunun \(w\) ve \(b\)’ye göre kısmi türevlerini bulmamız gerekir.
Kayıp Fonksiyonu: \(W\) Cinsinden#
Kayıp fonksiyonunun \(w\)’ye göre türevi:
\( \begin{align*} \frac{\partial }{\partial w} \left( MSE \right) &= \frac{\partial }{\partial w}[\frac{1}{n} \sum_{i=1}^{n}(y_{i}-(w x_{i} + b))^2] \\ &= \frac{1}{n} \sum_{i=1}^{n} \frac{\partial }{\partial w}[(y_{i}-(w x_{i} + b))^2] \\ &= \frac{2}{n} \sum_{i=1}^{n} (y_{i}-(w x_{i} + b))\frac{\partial }{\partial w}[y_{i}-(w x_{i} + b)] \\ &= \frac{2}{n} \sum_{i=1}^{n} (y_{i}-(w x_{i} + b))(-x_{i}) \\ &= -\frac{2}{n} \sum_{i=1}^{n}x_{i}(y_{i}-(w x_{i} + b)) \end{align*} \)
def mse_loss_dw(x, y, w, b):
return -2 * np.mean(x * (y - (w * x + b)))
Kayıp Fonksiyonu: \(b\) Cinsinden#
Kayıp fonksiyonunun \(b\)’ye göre türevi:
\( \begin{align*} \frac{\partial}{\partial b} \left( MSE \right) &= \frac{\partial }{\partial b}[\frac{1}{n} \sum_{i=1}^{n}(y_{i}-(w x_{i} + b))^2] \\ &= \frac{1}{n} \sum_{i=1}^{n} \frac{\partial }{\partial b}[(y_{i}-(w x_{i} + b))^2] \\ &= \frac{2}{n} \sum_{i=1}^{n} (y_{i}-(w x_{i} + b))\frac{\partial }{\partial b}[y_{i}-(w x_{i} + b)] \\ &= \frac{2}{n} \sum_{i=1}^{n} (y_{i}-(w x_{i} + b))(-1) \\ &= -\frac{2}{n} \sum_{i=1}^{n} (y_{i}-(w x_{i} + b)) \end{align*} \)
def mse_loss_db(x, y, w, b):
return -2 * np.mean(y - (w * x + b))
Doğrusal Regresyon Modelini Eğitmek#
Şimdi, biraz önce türettiğimiz gradyan denklemlerini kullanarak parametreleri güncelleyen bir fonksiyon tanımlayalım.
Genel gradyan inişi denklemi:
\( X_{n+1} = X_n - lr * \frac{\partial}{\partial X} f(X_n)\).
Sabit terim için gradyan inişi:
\( \begin{align*} b &= b - \eta \frac{\partial}{\partial b} [L(\vec{w}, b)] \\ &= b - \eta [-\frac{2}{n} \sum_{i=1}^{n} (y_{i}-(w x_{i} + b))] \end{align*} \)
Ağırlık için gradyan inişi:
\( \begin{align*} w &= w - \eta \frac{\partial}{\partial w} [L(\vec{w}, b)] \\ &= w - \eta [-\frac{2}{n} \sum_{i=1}^{n}x_{i}(y_{i}-(w x_{i} + b))] \end{align*} \)
def update_w_and_b(x, y, w, b, learning_rate):
# update w and b
w = w - mse_loss_dw(x, y, w, b) * learning_rate
b = b - mse_loss_db(x, y, w, b) * learning_rate
return w, b
Grafik Fonksiyonları#
Grafik çizimleri için yardımcı fonksiyonları tanımlayalım.
def create_plots():
plt.ioff()
fig = plt.figure(figsize=(16 / 9.0 * 4, 4 * 1), layout="constrained")
fig.suptitle("Gradyan İnişi")
ax0 = fig.add_subplot(1, 2, 1)
ax0.set_xlabel("Harcama", fontweight="normal")
ax0.set_ylabel("Satış", fontweight="normal")
ax0.set_title("Doğrusal Regresyon")
ax1 = fig.add_subplot(1, 2, 2, projection="3d")
ax1.set_xlabel("Eğim, w")
ax1.set_ylabel("Sabit Terim, b")
ax1.set_zlabel("Hata")
ax1.set_title("Hata")
ax1.view_init(15, -35)
camera = Camera(fig)
return ax0, ax1, camera
def generate_error_range(x, y, N, w_max, b_max):
w_range = np.arange(0, w_max, w_max / N)
b_range = np.arange(0, b_max, b_max / N)
w_range, b_range = np.meshgrid(w_range, b_range)
w_range = w_range.flatten()
b_range = b_range.flatten()
error_range = np.array([])
for i in range(min(w_range.shape[0], b_range.shape[0])):
error_range = np.append(error_range, mse_loss(x, y, w_range[i], b_range[i]))
return w_range, b_range, error_range
Modeli Eğitmek#
Eğitim fonksiyonu, her epokta parametreleri güncelleyecek ve görselleştirmeyi yenileyecek.
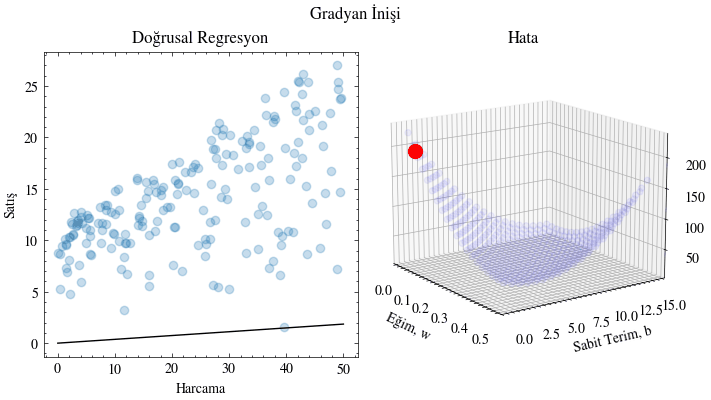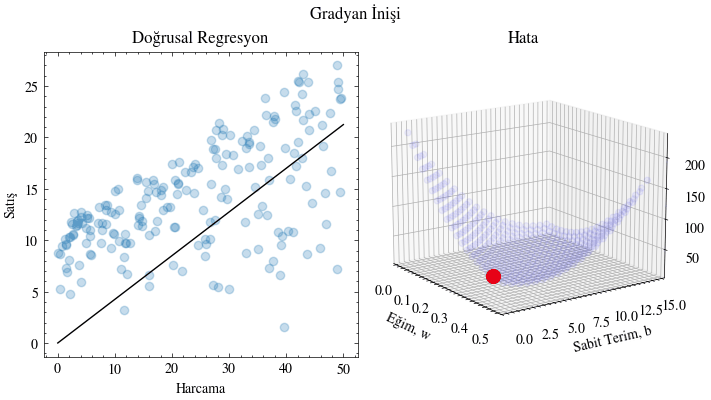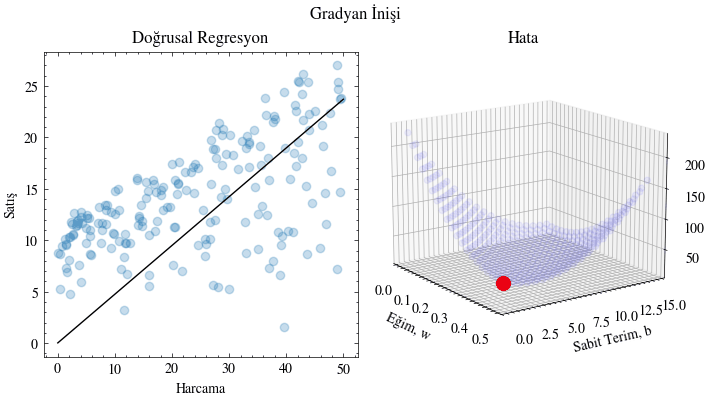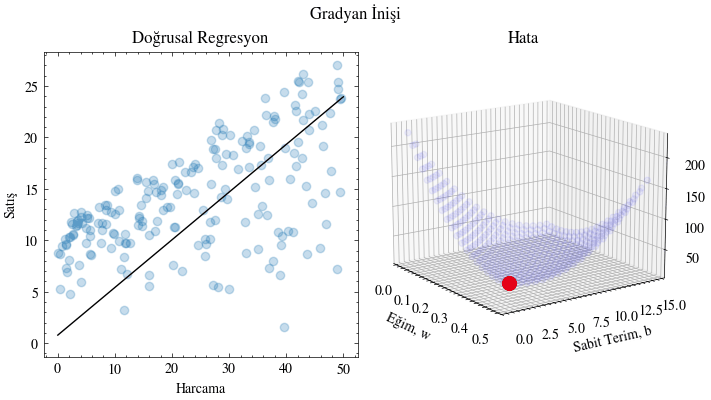
def train(x, y, w0, b0, learning_rate, epochs, output_filename):
w = w0
b = b0
ax0, ax1, camera = create_plots()
loss_dims = 20
w_max = 0.5
b_max = 15
w_range, b_range, error_range = generate_error_range(x, y, loss_dims, w_max, b_max)
for e in range(epochs):
w, b = update_w_and_b(x, y, w, b, learning_rate)
if (
(e == 0)
or (e < 60 and e % 5 == 0)
or (e < 3000 and e % 1000 == 0)
or (e % 3000 == 0)
):
# Plot the error given the current slope and y-intercept
ax1.scatter(w_range, b_range, error_range, color="blue", alpha=0.05)
ax1.scatter([w], [b], [mse_loss(x, y, w, b)], color="red", s=100)
# Plot the linear regression lines
ax0.scatter(x, y, color="#1f77b4", marker="o", alpha=0.25)
X_plot = np.linspace(0, 50, 50)
ax0.plot(X_plot, X_plot * w + b, color="black")
# print the loss
print("epok: ", str(e), "kayıp: " + str(mse_loss(x, y, w, b)))
camera.snap()
animation = camera.animate()
animation.save(output_filename, writer="pillow")
plt.show()
return w, b
Şimdi doğrusal regresyon modelimizi örnek veri kümesi üzerinde eğitelim.
fname = "REGRESSION-gradientDescent-data.txt"
x, y = np.loadtxt(fname, delimiter=",", unpack=True, skiprows=1, usecols=(2, 4))
output_filename = "gradient_descent.gif"
train(x, y, 0.0, 0, 0.00005, 4000, output_filename)
epok: 0 kayıp: 197.25274270926414
epok: 5 kayıp: 112.88939636458916
epok: 10 kayıp: 74.66409989764938
epok: 15 kayıp: 57.34204113744597
epok: 20 kayıp: 49.490344392988355
epok: 25 kayıp: 45.929244266843334
epok: 30 kayıp: 44.31200864892866
epok: 35 kayıp: 43.57543700948768
epok: 40 kayıp: 43.237843105871576
epok: 45 kayıp: 43.08099946508624
epok: 50 kayıp: 43.00603965880256
epok: 55 kayıp: 42.968173826457125
epok: 1000 kayıp: 41.62567353799647
epok: 2000 kayıp: 40.307849717949104
epok: 3000 kayıp: 39.06382181292731
/var/folders/x3/xmq8mst51mjb124_9bh98jy80000gn/T/ipykernel_56472/858932525.py:34: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
plt.show()
(np.float64(0.4560414772297029), np.float64(1.0259430403235812))
Image(filename=output_filename)