Temel Bileşen Analizi#
Makine öğrenmesi modelleri eğitilirken verilmesi gereken önemli kararlardan biri, hangi özelliklerin kullanılacağıdır. Temel Bileşen Analizi, varyansın büyük kısmını hangi özelliklerin açıkladığını görmenizi sağlar; böylece veri kümesini daha az sayıda ama birbiriyle ilişkili değişkene indirgemek mümkün olur.
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import scienceplots
from celluloid import Camera
from IPython.display import Image
np.random.seed(0)
plt.style.use(["science", "no-latex"])
Hedef Veri Kümesi#
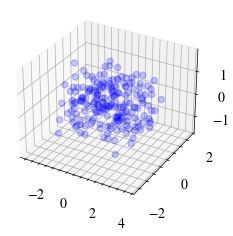
Başlangıç ve bitiş noktaları arasında değerler üretip her noktaya rastgele gürültü ekleyerek gürültülü bir nokta kümesi oluşturalım.
def generate_noisy_hyperplane(num_points, start_pt, end_pt, noise=0.25):
# create a plane from the start to the end point
t = np.linspace(0.0 + noise, 1.0 - noise, num_points).reshape(-1, 1)
points = start_pt + t * (end_pt - start_pt)
# add noise to plane
noise = np.random.normal(0, noise, size=(num_points, 3))
points = points + noise
return points
start_pt = np.array([-1, -1, -1])
end_pt = np.array([1, 1, 1])
X = generate_noisy_hyperplane(200, start_pt, end_pt)
# plot the points
fig = plt.figure()
ax = fig.add_subplot(111, projection="3d")
ax.scatter(X[:, 0], X[:, 1], X[:, 2], alpha=0.2, color="blue", label="Orijinal Veri")
plt.show()
Özvektörler ve Özdeğerler#
Bir matrisi özvektörüyle çarptığınızda, elde ettiğiniz sonuç özvektörün bir skaler katı olur. Bu skaler katsayı, ilgili özvektörün özdeğeridir. Bir matrisin özvektör ve özdeğerlerini bulma sürecine özdeğer ayrışımı denir.
Burada \(\lambda\) özdeğeri, \(\vec{v}\) ise buna karşılık gelen özvektörü ifade eder. Özdeğer ayrışımı genellikle \(det(A - \lambda I) = 0\) determinantını çözmeyi içerir; burada \(I\) birim matristir.
Bir matrisin özdeğer ve özvektörlerini hızlıca bulmak için NumPy kullanılabilir.
import numpy as np
mat = np.array([[4, -2],
[1, 1]])
eig_vals, eig_vecs = np.linalg.eig(mat)
Lagrange Çarpanları (Kısıtlı Optimizasyon)#
Çok değişkenli analizden hatırlayacağınız gibi, Lagrange çarpanları, \(g(x, y, z, ...)=0\) kısıtı altında tanımlanan \(f(x, y, z, ...)\) fonksiyonunun ekstremumlarını bulmayı sağlar.
Lagrange çarpanları yöntemine göre bu kısıtlı optimizasyon probleminin çözümü, aşağıdaki denklem sisteminin çözümüdür:
burada
PCA’nın Türetilmesi (Kovaryans Matrisinin Özdeğer Ayrışımı)#
Amacımızın, varyansın en büyük kısmını açıklayan \(v\) vektörlerini bulmak olduğunu hatırlayalım.
Girdi vektörü \(x_i\) ve vektör \(v\) verildiğinde, her girdi noktasını her boyutta \(v\) üzerine izdüşürmek isteriz.
Varyans ise şu şekilde yazılır:
\(n\) boyutun tüm izdüşümleri üzerindeki varyansı en büyük yapmak için:
\( \begin{align*} \max \sum_{i=1}^{n} (x_i^Tv)^2 &= \max \sum_{i=1}^{n} z_i^2 \\ &= \max z^Tz \\ &= \arg\max (xv)^Txv \\ \end{align*} \)
PCA’da önemli olan şey temel bileşenlerin oranları olduğundan, şu kısıtı ekleyelim: $\(v^Tv = 1\)$
Kısıtlı optimizasyon problemini Lagrange çarpanlarıyla çözerken Lagrange fonksiyonunu şöyle tanımlarız:
Şimdi \(\nabla L = 0\) koşulunu çözerek Lagrange fonksiyonunu inceleyelim:
\( \begin{align*} 0 &= \frac{\partial L}{\partial v} \\ &= \frac{\partial}{\partial v}[v^Tx^Txv - \lambda (v^Tv - 1)] \\ &= 2x^Txv - 2\lambda v \\ &= x^Txv - \lambda v \\ &= (x^Tx)v - \lambda v \\ (x^Tx)v &= \lambda v \\ \end{align*} \)
\(x^Tx\)’in bir matrisin kovaryansı olduğunu düşünürsek, PCA çözümünün aslında kovaryans matrisinin özdeğer ayrışımı olduğunu görürüz.
PCA’nın Uygulanması#
Yukarıdaki iki bölümü özetlersek, PCA şu adımlardan oluşur:
Girdi verisini, veriden ortalamayı çıkarıp standart sapmaya bölerek standartlaştırmak
Standartlaştırılmış girdinin kovaryans matrisini hesaplamak
Kovaryans matrisinin özdeğerlerini ve özvektörlerini bulmak
İzdüşürülen veriyi elde etmek için standartlaştırılmış girdiyi özvektörlerle çarpmak
def pca(X, dims):
# subtract the mean to center the data and divide by standard deviation
X_centered = (X - np.mean(X, axis=0)) / np.std(X, axis=0)
# compute covariance matrix
cov = np.cov(X_centered.T)
# eigendecomposition of the covariance matrix
# the eigenvectors are the principal components
# the principal components are the columns of the eig_vecs matrix
eig_vals, eig_vecs = np.linalg.eig(cov)
# sort the eigenvalues and eigenvectors
sorted_idx = np.argsort(eig_vals)[::-1]
eig_vals = eig_vals[sorted_idx]
eig_vecs = eig_vecs[:, sorted_idx]
# perform dimensionality reduction using the computed principal components
# if you want to reduce to K dimensions, simplify take the first K columns
projected = X_centered @ eig_vecs
# compute the variance of each dimension (column)
pc_variances = [np.var(projected[:, i]) for i in range(dims)]
return eig_vals, eig_vecs, projected, pc_variances
Grafik Fonksiyonları#
Görselleştirmeleri üretmek için yardımcı fonksiyonlar.
def create_plots():
fig = plt.figure(figsize=(16 / 9.0 * 4, 4 * 1))
fig.suptitle("Temel Bileşen Analizi")
ax0 = fig.add_subplot(121, projection="3d")
ax0.set_xlabel("X")
ax0.set_ylabel("Y")
ax0.set_zlabel("Z")
ax0.set_title("TB Hiper Düzlemleri")
ax0.view_init(17, -125, 2)
ax0.set_xlim(-1, 1)
ax0.set_ylim(-1, 1)
ax0.set_zlim(-1, 1)
ax0.tick_params(axis="both", which="both", length=0)
ax1 = fig.add_subplot(122, projection="3d")
ax1.set_xlabel("X")
ax1.set_ylabel("Y")
ax1.set_zlabel("Z")
ax1.set_title("Projeksiyon Verisi")
ax1.view_init(17, -125, 2)
# ax1.set_xlim(-1, 1)
# ax1.set_ylim(-1, 1)
# ax1.set_zlim(-1, 1)
ax1.tick_params(axis="both", which="both", length=0)
# plt.axis('equal')
camera = Camera(fig)
return ax0, ax1, camera
def plot_hyperplane(ax, pc_vector, color="red", scaling=10, alpha=0.3):
# Create a grid of points
points = np.linspace(-1, 1, scaling)
xx, yy = np.meshgrid(points, points)
# the z value is the defined by the hiper düzlem from the principal component vector
pc_vector /= np.linalg.norm(pc_vector)
z = (-pc_vector[0] * xx - pc_vector[1] * yy) / pc_vector[2]
ax.plot_surface(xx, yy, z, color=color, alpha=alpha)
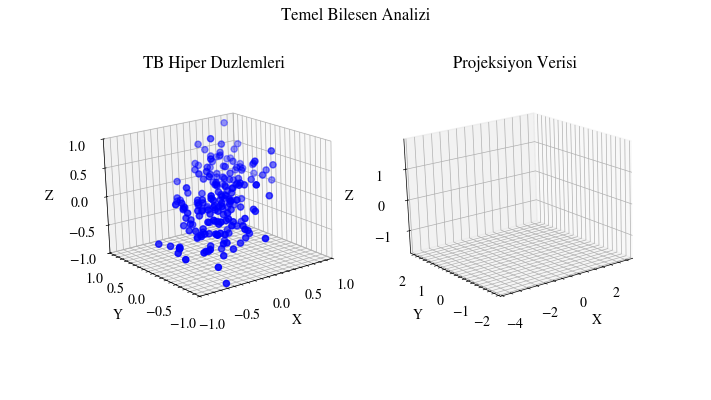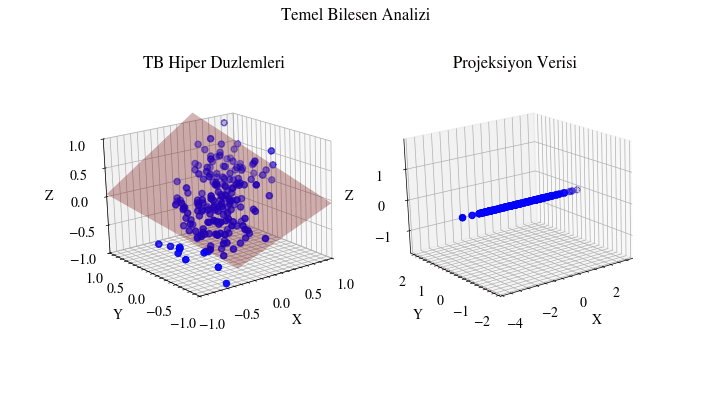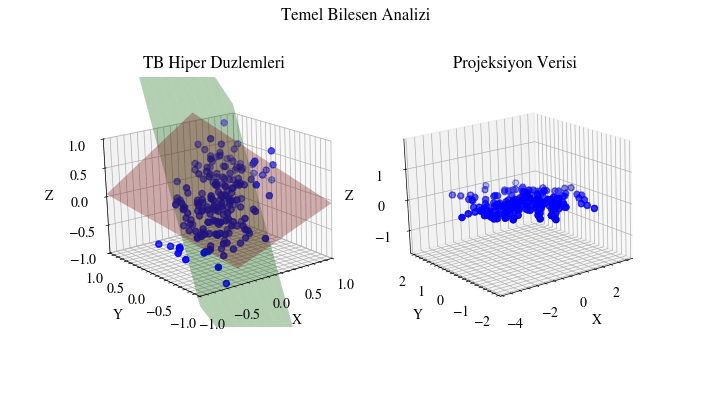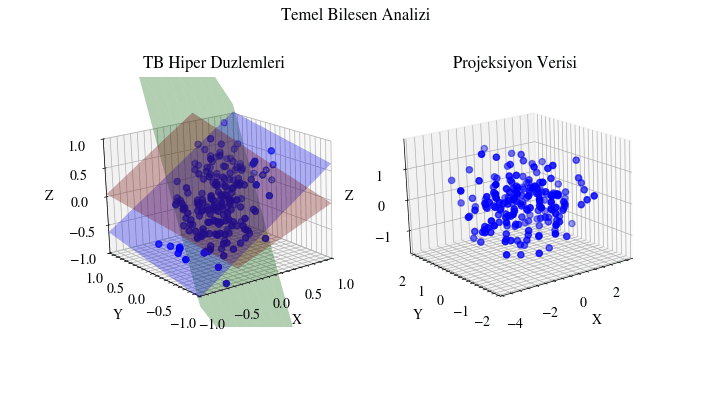
PCA’yı Görselleştirmek#
PCA türetimini gördüğümüze göre, şimdi hedef boyut için farklı değerler seçerek izdüşürülen veriyi görselleştirelim.
def visualize_pca(X, dims, output_filename):
ax0, ax1, camera = create_plots()
colors = ["red", "green", "blue"]
for dim in range(0, dims + 1):
eig_vals, eig_vecs, projected, pc_variances = pca(X, dims)
# plot the original data
ax0.scatter(X[:, 0], X[:, 1], X[:, 2], color="blue", label="Orijinal Veri")
# plot the pca hyperplanes
for i in range(dim):
plot_hyperplane(ax0, eig_vecs[:, i], color=colors[i])
# plot the projected data from the principal components
curr_projected = projected
for i in range(dim, dims):
if i < dims:
curr_projected[:, i] = 0
if dim != 0:
ax1.scatter(
curr_projected[:, 0],
curr_projected[:, 1],
curr_projected[:, 2],
color="blue",
label="Projeksiyon Verisi",
)
camera.snap()
animation = camera.animate(interval=2000)
animation.save(output_filename, writer="pillow")
plt.show()
eig_vals, eig_vecs, projected, pc_variances = pca(X, dims)
print("her temel bileşen için varyans yüzdesi")
variance_percentage = eig_vals / np.sum(eig_vals)
for i, percentage in enumerate(variance_percentage):
print(f"{i+1}th PC: {round(percentage*100, 2)}%")
print("her temel bileşen için varyans")
for i, variance in enumerate(pc_variances):
print(f"{i+1}th PC: {round(variance, 2)}")
print("\nhiper düzlemler")
for i in range(dim):
print(f"hiper düzlem {i}: {eig_vecs[:, i]}")
dims = 3
output_filename = "pca.gif"
visualize_pca(X, dims, output_filename)
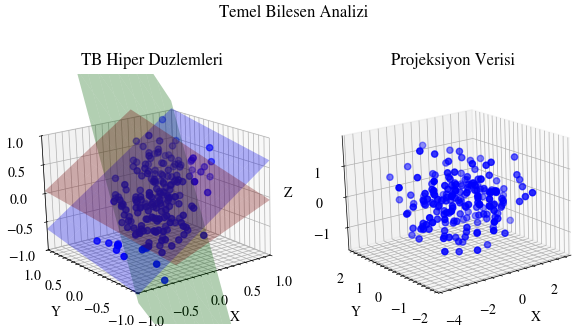
her temel bileşen için varyans yüzdesi
1th PC: 69.12%
2th PC: 17.52%
3th PC: 13.36%
her temel bileşen için varyans
1th PC: 2.07
2th PC: 0.53
3th PC: 0.4
hiper düzlemler
hiper düzlem 0: [-0.58180084 -0.55533668 -0.59422972]
hiper düzlem 1: [ 0.51390531 -0.81729222 0.26064299]
hiper düzlem 2: [-0.63040394 -0.1537355 0.76089176]
Image(filename=output_filename)
Scikit-Learn ile Uygulama#
Doğruluğu kontrol etmek için sonuçlarımızı scikit-learn içindeki PCA modülüyle karşılaştıralım.
Not: İşaretler birebir aynı olmayabilir. Önemli olan oranların aynı olmasıdır; burada da durum bu. Bizim uygulamamız scikit-learn ile eşleşiyor.
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_centered = scaler.fit_transform(X)
pca = PCA(n_components=dims)
projected = pca.fit_transform(X_centered)
eig_vecs = pca.components_
print("\nhiper düzlemler")
for i in range(dims):
print(f"hiper düzlem {i}: {eig_vecs[i]}")
hiper düzlemler
hiper düzlem 0: [0.58180084 0.55533668 0.59422972]
hiper düzlem 1: [-0.51390531 0.81729222 -0.26064299]
hiper düzlem 2: [-0.63040394 -0.1537355 0.76089176]
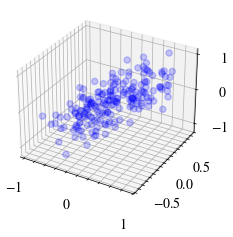
Şimdi scikit-learn ile elde edilen izdüşürülmüş veriyi de çizelim. Görünen o ki bizim uygulamamız izdüşürülmüş veride de aynı sonucu veriyor.
fig = plt.figure()
ax = fig.add_subplot(111, projection="3d")
ax.scatter(projected[:, 0], projected[:, 1], projected[:, 2], alpha=0.2, color="blue", label="Projeksiyon Verisi")
plt.show()