0.0 Temel Kavramlar — Makine Öğrenmesine Giriş
Bu metin, makine öğrenmesinin temel kavramlarını, herhangi bir uygulama alanına geçmeden önce edinilmesi gereken düzeyde sunar. Anlatım, teknik doğruluğu korurken kavramsal erişilebilirliği ön planda tutar. Tarımsal örnekler yalnızca kavramı somutlaştırmak için ve epistemik durumları açıkça belirtilerek verilmiştir.
1. Veri Yapıları ve Ön İşleme
1.1 Veri Türleri
Tanım
Makine öğrenmesi modelleri farklı biçimlerdeki verilerle çalışır. Temel ayrım şu şekilde yapılabilir:
- Sayısal (Numerical): Sürekli veya kesikli ölçülebilir büyüklükler. Sürekli örnek: sıcaklık (C); kesikli örnek: dal sayısı.
- Kategorik (Categorical): Sonlu sayıda sınıf veya etiket. Nominal (sırasız: toprak tipi) veya ordinal (sıralı: düşük/orta/yüksek verimlilik) olabilir.
- Metin (Text): Doğal dil biçiminde yapılandırılmamış veri.
- Görüntü (Image): Piksel değerlerinden oluşan matris ya da tensör yapısı.
- Zaman Serisi (Time Series): Zamana göre indekslenmiş ardışık gözlemler.
Neden Gerekli?
Veri türü, uygulanabilecek ön işleme adımlarını, uygun model ailelerini ve değerlendirme stratejilerini doğrudan belirler. Kategorik bir değişkeni sayısal olarak kodlamadan birçok algoritmaya girdi olarak vermek mümkün değildir; görüntü verisine tablolu veri yöntemleri doğrudan uygulanamaz.
Tarımsal Bağlamda Yeri
Tarım, doğası gereği çok kaynaklı ve çok türlü veri üreten bir alandır. Bu çeşitlilik, tarımsal makine öğrenmesi projelerini diğer uygulama alanlarından ayıran temel bir özelliktir. Aşağıda her veri türü, tarımsal kaynakları ve modelleme açısından önemiyle birlikte sunulmaktadır.
Sayısal Veriler
Temsili veri şeması (gerçek veri değildir):
| Kaynak | Değişken | Birim | Tipik Aralık | Temsil Ettiği Süreç |
|---|---|---|---|---|
| Toprak sensörü | Toprak nemi | % | 10–55 | Kök bölgesi su erişilebilirliği |
| Toprak sensörü | pH | — | 4.0–9.0 | Besin elementi alınabilirliği |
| Toprak sensörü | Elektriksel iletkenlik (EC) | dS/m | 0–20 | Tuzluluk stresi |
| Meteoroloji ist. | Günlük yağış | mm | 0–150 | Su bütçesi girdisi |
| Meteoroloji ist. | Günlük ortalama sıcaklık | °C | -5–45 | Büyüme hızı, don riski |
| Meteoroloji ist. | Bağıl nem | % | 20–100 | Evapotranspirasyon, hastalık riski |
| Bitki ölçümü | Yaprak alanı indeksi (LAI) | m2/m2 | 0–8 | Fotosentetik kapasite |
| Bitki ölçümü | Klorofil içeriği (SPAD) | — | 20–60 | Azot durumu |
| Hasat kaydı | Verim | ton/ha | 1–12 | Üretim çıktısı (hedef değişken) |
Bu değişkenlerin ölçek farklılıkları (pH: 4–9, yağış: 0–150, LAI: 0–8) modelleme öncesinde ölçekleme gerekliliğini doğrudan ortaya koyar.
Kategorik Veriler
Temsili değişken şeması:
| Değişken | Tür | Olası Değerler | Modeldeki Rolü |
|---|---|---|---|
| Toprak tipi | Nominal | Kumlu, killi, tınlı, siltli-killi-tınlı, ... | Su tutma kapasitesi ve drenaj farklılıkları |
| Sulama yöntemi | Nominal | Damla, yağmurlama, karık, kuru tarım | Su kullanım verimliliği ayrımı |
| Arazi kullanımı | Nominal | Tarla, mera, orman, yerleşim | Arazi örtüsü sınıflandırması |
| Çeşit/Kultivar | Nominal | Yüzlerce olası değer | Genetik verim potansiyeli |
| Hastalık varlığı | İkili | Var / Yok | Sınıflandırma hedef değişkeni |
| Hastalık şiddeti | Ordinal | Yok / Hafif / Orta / Şiddetli | Sıralı regresyon veya sınıflandırma |
| Ekim sistemi | Nominal | Monoculture, münavebe, karışık ekim | Verim ve hastalık dinamiği ayrımı |
Kategorik değişkenler, modelin koşulları ayırt etmesini sağlar: aynı iklim verisi altında damla sulama ile kuru tarım yapılan iki parselin verim dinamikleri farklıdır.
Görüntü Verileri
Tarımda son on yılda en hızlı büyüyen veri türüdür. Farklı platformlar farklı bilgi katmanları sunar:
1. RGB hava fotoğrafı (drone/uçak): Santimetre düzeyinde çözünürlükte görünür bant görüntüleri. Bitki sıra yapısı, boşluk oranı ve genel tarla durumu gözlemlenir.

Drone ile çekilmiş pirinç tarlası RGB görüntüsü (Aomori, Japonya). Kaynak: Wikimedia Commons, CC BY-SA 4.0.
2. Uydu görüntüsü (Sentinel-2 / Copernicus): Çok bantlı (multispektral) uydu verileri, tarla ölçeğinde mekansal heterojenliği ve zaman içindeki bitki örtüsü değişimini yansıtır. Tipik çözünürlük: 10–60 m/piksel.
Sentinel-2 uydu görüntüsü — Avusturya ve Slovakya tarım arazileri (Copernicus, 2024). Kaynak: Wikimedia Commons, CC BY-SA 4.0, ESA.
3. Hava fotoğrafı (yüksek irtifa): Tarla parsellerinin mekansal düzeni, ürün çeşitliliği ve arazi kullanım yapısı makro ölçekte görülür.

Tarla parsellerinin hava fotoğrafı (Dülmen, Almanya, 2024). Kaynak: Wikimedia Commons, CC BY-SA 4.0, Dietmar Rabich.
4. NDVI haritası: Normalized Difference Vegetation Index — NIR ve kırmızı bantlardan türetilen bitki sağlığı indeksi. Yeşil alanlar yüksek fotosentetik aktiviteyi, sarı-kırmızı alanlar stres veya çıplak toprağı gösterir.
NDVI haritası (Lublin bölgesi). Kaynak: Wikimedia Commons, CC BY-SA 4.0.
5. NDVI — sulanan tarla detayı: Parsel düzeyinde NDVI dağılımı, sulama ve verimlilik farklılıklarını görsel olarak ayırt etmeye olanak tanır.
Sulanan tarla parsellerinin NDVI görüntüsü. Kaynak: Wikimedia Commons, CC BY-SA 3.0.
Bu görüntülerin her biri farklı piksel boyutu, bant sayısı ve mekansal referans sistemiyle gelir; ön işleme gereksinimleri (geometrik düzeltme, atmosferik düzeltme, bant hizalama) tablolu veriden temelden farklıdır.
Zaman Serisi Verileri
Bitki büyümesi, toprak nemi değişimi ve iklimsel koşullar zamanla değişen süreçlerdir. Bu verilerin temel özelliği, gözlemlerin birbirinden bağımsız olmamasıdır (otokorelasyon). Bu yapı, hem model seçimini (LSTM, ARIMA, Transformer) hem de doğrulama stratejisini (kronolojik bölünme zorunluluğu) doğrudan etkiler.
Temsili veri (gerçek ölçüm değildir) — 6 aylık büyüme dönemi izleme:
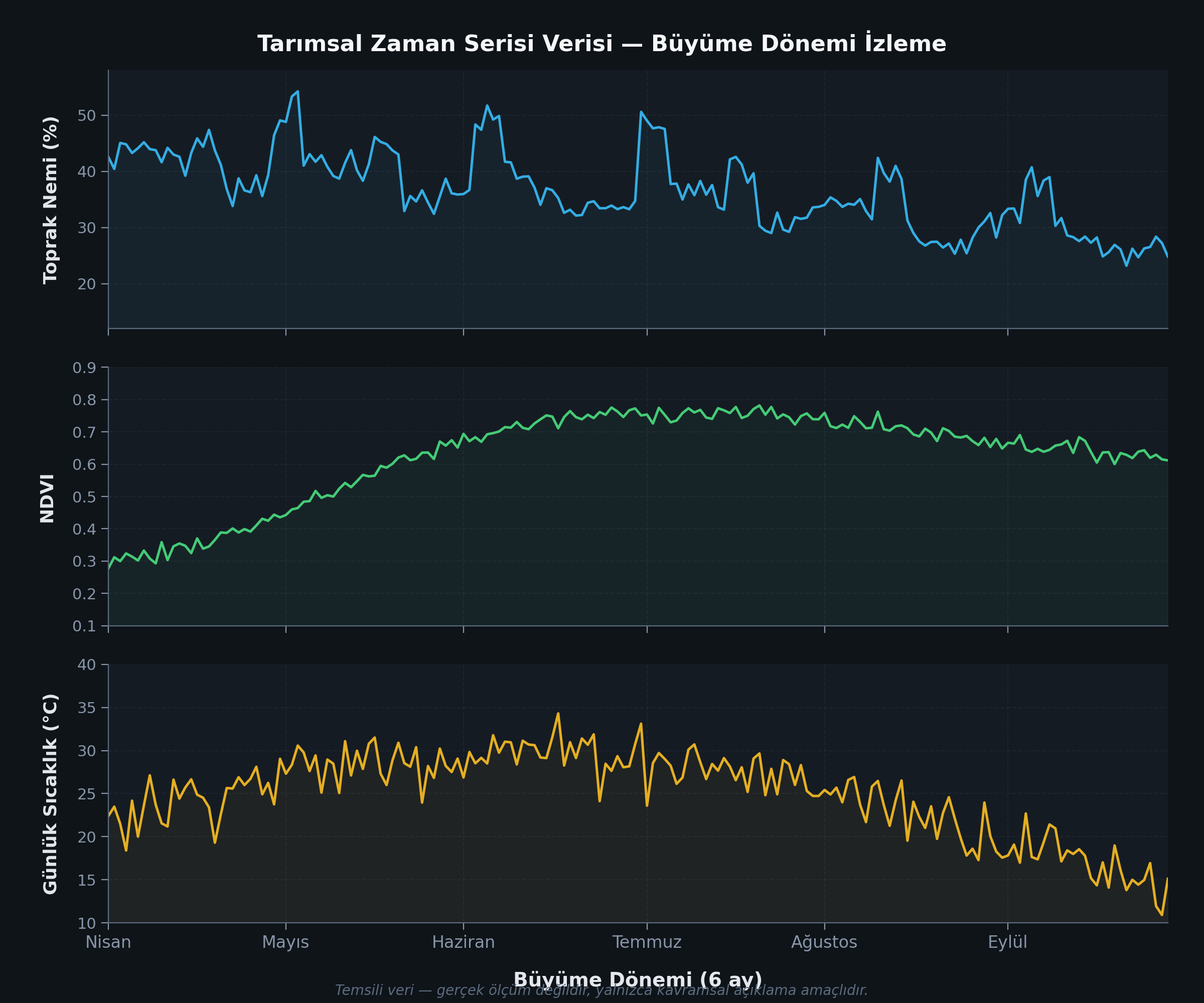
Temsili zaman serisi: toprak nemi (%), NDVI ve günlük sıcaklık (°C). Yağış olaylarının toprak nemine ani etkisi, NDVI'nın mevsimsel büyüme eğrisi ve sıcaklığın sinüzoidal yapısı gözlemlenmektedir. Bu veri gerçek ölçüm değildir.
Metin ve Mekansal Veriler
Metin verileri (tarla notları, uzman raporları, araştırma makaleleri) yapılandırılmış veri setlerinde yer almayan bağlamsal bilgi taşır. Mekansal veriler (GPS koordinatlı örnekler, parsel sınırları, eğim haritaları) diğer türlere ek boyut olarak eşlik eder. Mekansal otokorelasyon, modelleme ve doğrulamada dikkate alınması gereken bir yapıdır.
Bütünsel değerlendirme: Tek bir verim tahmini çalışmasında bu türlerin çoğu bir arada bulunabilir. Bu çok kaynaklı yapı, veri birleştirme (data fusion) ve her türe özgü ön işleme adımlarını zorunlu kılar.
1.2 Eğitim / Doğrulama / Test Ayrımı
Tanım
Veri seti, modelin öğrenme ve değerlendirme süreçlerini birbirinden ayırmak için alt kümelere bölünür:
| Küme | İşlev | Yaygın Oran |
|---|---|---|
| Eğitim (Train) | Model parametrelerinin öğrenilmesi | %60–80 |
| Doğrulama (Validation) | Hiperparametre seçimi, erken durdurma kararı | %10–20 |
| Test | Modelin nihai, bağımsız performans ölçümü | %10–20 |
Neden Gerekli?
Test verisi, model geliştirme sürecinde herhangi bir karar için kullanılırsa, performans tahminleri yukarı yönlü sapma gösterir. Bu durum veri sızıntısı (data leakage) olarak adlandırılır ve modelin gerçek genelleme kapasitesinin olduğundan yüksek görünmesine yol açar.
Sınırlar / Hatalı Kullanımlar
- Küçük veri setlerinde sabit bölünme, yüksek varyansa sahip performans tahminleri üretebilir. Bu durumda çapraz doğrulama tercih edilmelidir (bkz. 4.4).
- Zaman serisi verisinde rastgele bölünme, zamansal sızıntıya neden olabilir. Kronolojik bölünme kullanılmalıdır.
1.3 Özellik Mühendisliği (Feature Engineering)
Tanım
Ham veriden, modelin öğrenme kapasitesini artırması beklenen yeni girdi değişkenleri türetme sürecidir.
Neden Gerekli?
Ham değişkenler, hedef değişkenle doğrudan ilişkili olmayabilir. Türetilmiş özellikler, verinin bilgi içeriğini modelin erişebileceği biçime dönüştürür. Özellik mühendisliğinin kalitesi, özellikle klasik (derin olmayan) modellerde, model performansını belirleyen başlıca etkenlerden biridir.
Tarımsal Bağlamda Yeri
Tipik uygulama örneği: Uzaktan algılama çalışmalarında, ham spektral bant değerleri yerine bu bantlardan türetilen indeksler (örn. NDVI = (NIR − Red) / (NIR + Red)) kullanılması yaygındır. Bu tür türetmelerin gerçek katkısı probleme ve verinin yapısına bağlıdır; otomatik olarak ham bantlardan üstün olduğu varsayılmamalıdır.
1.4 Veri Ön İşleme
Tanım
Ham veriyi, modelin girdi gereksinimlerine uygun hale getirmek için uygulanan dönüşüm adımlarıdır.
Temel İşlemler
Ölçekleme (Scaling)
Farklı birim ve aralıklardaki özellikleri ortak ölçeğe getirme işlemidir. Min-Max normalizasyonu değerleri [0,1] aralığına, Z-score standardizasyonu sıfır ortalama ve birim varyansa dönüştürür. Uzaklık tabanlı algoritmalar (k-NN, SVM) ölçeklemeye özellikle duyarlıdır.
Tarımsal bağlam: pH (4–9), yağış (0–150 mm), LAI (0–8 m2/m2) gibi değişkenler çok farklı ölçeklerdedir. Ölçekleme yapılmazsa, geniş aralıklı değişkenler uzaklık tabanlı algoritmalarda dar aralıklıları baskılar — agronomik açıdan kritik olan pH, modelde görünmez hale gelebilir.
Eksik Veri İşleme
Silme (listwise/pairwise), ortalama/medyan ile doldurma veya model tabanlı impütasyon yöntemleri uygulanabilir. Yöntem seçimi, eksikliğin mekanizmasına (MCAR — tamamen rastgele, MAR — koşullu rastgele, MNAR — rastgele olmayan) bağlıdır.
Tarımsal bağlam: Tarla koşullarında eksik veri sıradan değil, yapısaldır. Toprak nem sensörleri aşırı kuraklıkta ölçüm aralığının dışına çıkabilir; yağış ölçerler donma döneminde çalışmayabilir; drone uçuşları bulutlu veya rüzgarlı günlerde iptal edilir; uydu görüntüleri bulut örtüsü altında kayıp piksel içerir. Bu eksikliklerin her birinin mekanizması farklıdır: sensör arızası rastgele olabilir, ancak bulut örtüsü nedeniyle kayıp uydu pikselleri sistematik olarak yağışlı dönemlere denk gelir — yani bitki stresinin en kritik olabileceği dönemler paradoksal biçimde en az gözlemlenen dönemlerdir. Bu durumda basit ortalama ile doldurma ciddi bir bilgi kaybı yaratır: kuraklık dönemindeki toprak nemini yıllık ortalamayla doldurmak, gerçek stres koşullarını maskeleyerek modelin stres-verim ilişkisini öğrenme kapasitesini zayıflatır. Zamansal yapıyı koruyan impütasyon yöntemleri (zaman pencereli interpolasyon, Kalman filtresi tabanlı yaklaşımlar) veya en azından mevsimsel medyan ile doldurma, tarımsal verilerde koşulsuz ortalamaya göre daha savunulabilir seçeneklerdir.
Kategorik Kodlama
Nominal değişkenlerde One-Hot Encoding, ordinal değişkenlerde sıralı tamsayı kodlama yaygındır. Yüksek kardinalite durumunda target encoding gibi alternatifler değerlendirilebilir.
Tarımsal bağlam: Tarımsal veri setlerinde kategorik değişkenler genellikle alan bilgisiyle doğrudan ilişkili sınıflandırmalardır. Toprak tipi (kumlu, killi, tınlı, siltli-killi-tınlı vb.), sulama yöntemi (damla, yağmurlama, karık, yüzey, kuru tarım), ekim sistemi (monoculture, münavebe, consociasyon), çeşit/kultivar adı ve hastalık türü gibi değişkenler modele dahil edilir. Bu değişkenlerin kodlama yöntemi, modelin bunları nasıl kullandığını doğrudan belirler. Toprak sınıflandırma sistemlerinde (USDA, FAO) düzinelerce alt sınıf bulunabilir; bu yüksek kardinaliteyi One-Hot ile kodlamak özellik uzayını aşırı genişletir ve seyreklik (sparsity) problemi yaratır. Çeşit adları da benzer biçimde yüzlerce kategori içerebilir. Bu durumlarda target encoding (hedef değişkenin sınıf bazında ortalamasıyla kodlama) veya ağaç tabanlı modellerin doğal kategorik desteği daha uygun olabilir. Ordinal yapılar da dikkate alınmalıdır: hastalık şiddeti (yok / hafif / orta / şiddetli) sıralı bir yapı taşır ve bu sıralılığı koruyan kodlama (0, 1, 2, 3) modelin gradyan ilişkisini öğrenmesine yardımcı olabilirken, One-Hot kodlama bu bilgiyi yok eder.
Aykırı Değer İşleme
Tarımsal bağlam: Tarla verisinde aykırı değerler iki farklı kaynaktan gelebilir: ölçüm hatası veya gerçek biyolojik/çevresel olay. Toprak nem sensörünün geçici olarak hava ile temas kaybetmesi sonucu verdiği negatif değer bir ölçüm hatasıdır ve temizlenmelidir. Ancak bir parseldeki beklenmedik verim düşüşü, yerel dolu hasarı veya kök çürüklüğü gibi gerçek bir olayı yansıtıyor olabilir — bu gözlemi otomatik olarak silmek, modelin olağandışı koşulları öğrenme kapasitesini kısıtlar. Tarımsal verilerde aykırı değer kararı, alan bilgisi gerektiren bir değerlendirme sürecidir; istatistiksel eşik (IQR, z-skoru) tek başına yeterli bir kriter değildir.
Sınırlar / Hatalı Kullanımlar
- Ölçekleme parametrelerinin (ortalama, standart sapma) test verisi dahil edilerek hesaplanması veri sızıntısı oluşturur. Bu parametreler yalnızca eğitim setinden türetilmelidir.
- Mevsimsel yapı taşıyan eksik verilerde koşulsuz ortalama ile doldurma, yapay olarak düşük varyans üretebilir ve gerçek stres dönemlerini maskeleyebilir.
- Yüksek kardinaliteli kategorik değişkenlerde One-Hot kodlama, seyrek ve yüksek boyutlu özellik uzayı oluşturarak küçük veri setlerinde overfitting riskini artırır.
- Tarla verisindeki aykırı değerlerin otomatik silinmesi, gerçek biyolojik olayların kaybına yol açabilir; alan bilgisi olmadan istatistiksel eşik uygulamak risklidir.
Kısa Kavrama Kontrolü
Yanıt
Birleşik hesaplama durumunda, test verisinin ortalama ve standart sapma bilgisi ölçekleme parametrelerine sızar. Bu, test örneklerinin dönüştürülmüş değerlerinin eğitim sırasında dolaylı olarak "görülmüş" olması anlamına gelir. Sonuç olarak test seti performansı yukarı yönlü sapma gösterir — model, gerçekte sahip olmadığı bir genelleme kapasitesine sahipmiş gibi görünür. Bu durum veri sızıntısı (data leakage) olarak adlandırılır. Doğru yaklaşım, ölçekleme parametrelerinin yalnızca eğitim setinden hesaplanması ve aynı parametrelerin test setine uygulanmasıdır (fit yalnızca eğitimde, transform hem eğitim hem testte).
2. Öğrenme Paradigmaları
2.1 Denetimli Öğrenme (Supervised Learning)
Tanım
Girdi-çıktı çiftlerinden (X, y) oluşan etiketli veri kullanılarak, f: X → y eşlemesini yaklaştıran bir model öğrenilir.
- Sınıflandırma: Hedef değişken sonlu sayıda kategoriden oluşur.
- Regresyon: Hedef değişken sürekli bir niceliktir.
Neden Gerekli?
Etiketli verinin mevcut olduğu ve spesifik bir tahmin hedefinin tanımlanabildiği durumlarda en doğrudan yaklaşımdır. Model başarısı, etiketlerin kalitesine ve temsil gücüne doğrudan bağlıdır.
Tarımsal Bağlamda Yeri
Sınıflandırma örneği — Yaprak hastalığı tespiti: Denetimli sınıflandırmanın tarımdaki en yaygın uygulamalarından biri, yaprak görüntülerinden hastalık tanımadır. Model, etiketlenmiş görüntülerden (sağlıklı / hasta) hastalık belirtilerinin görsel örüntülerini öğrenir. Aşağıdaki görüntü, domates yaprağında geç yanıklık (Phytophthora infestans) belirtilerini göstermektedir — koyu kahverengi nekrotik lezyonlar ve yaprak kıvrılması tipik sınıflandırma etiketleme unsurlarıdır.

Domates yaprağında geç yanıklık (Phytophthora infestans). Kaynak: Wikimedia Commons, CC BY 2.0, Scot Nelson.
Bir sınıflandırma modelinin bu görüntüyü işleme biçimi şu şekilde özetlenebilir: girdi olarak yaprak görüntüsü (piksel matrisi) alınır; model, eğitim aşamasında binlerce etiketli görüntüden hastalık belirtilerinin uzamsal ve renk örüntülerini öğrenir; çıktı olarak sınıf etiketi (sağlıklı / geç yanıklık / erken yanıklık / septoria vb.) ve her sınıfa ait olasılık tahmini üretir. Sınıflandırma doğruluğu, etiketlerin tutarlılığına (uzman doğrulaması), görüntü kalitesine (çözünürlük, aydınlatma koşulları) ve eğitim setinin sınıf dağılımına doğrudan bağlıdır.
Regresyon örneği — Verim tahmini: Denetimli regresyon, sürekli bir niceliktir olan hedef değişkeni tahmin eder. Tarımda en yaygın regresyon problemi verim tahminidir: iklim değişkenleri, toprak parametreleri ve yönetim uygulamalarından hareketle birim alan başına ürün miktarı (ton/ha) öngörülmeye çalışılır.
Aşağıdaki grafik, yıllık yağış miktarı ile buğday verimi arasındaki doğrusal regresyon ilişkisini göstermektedir:
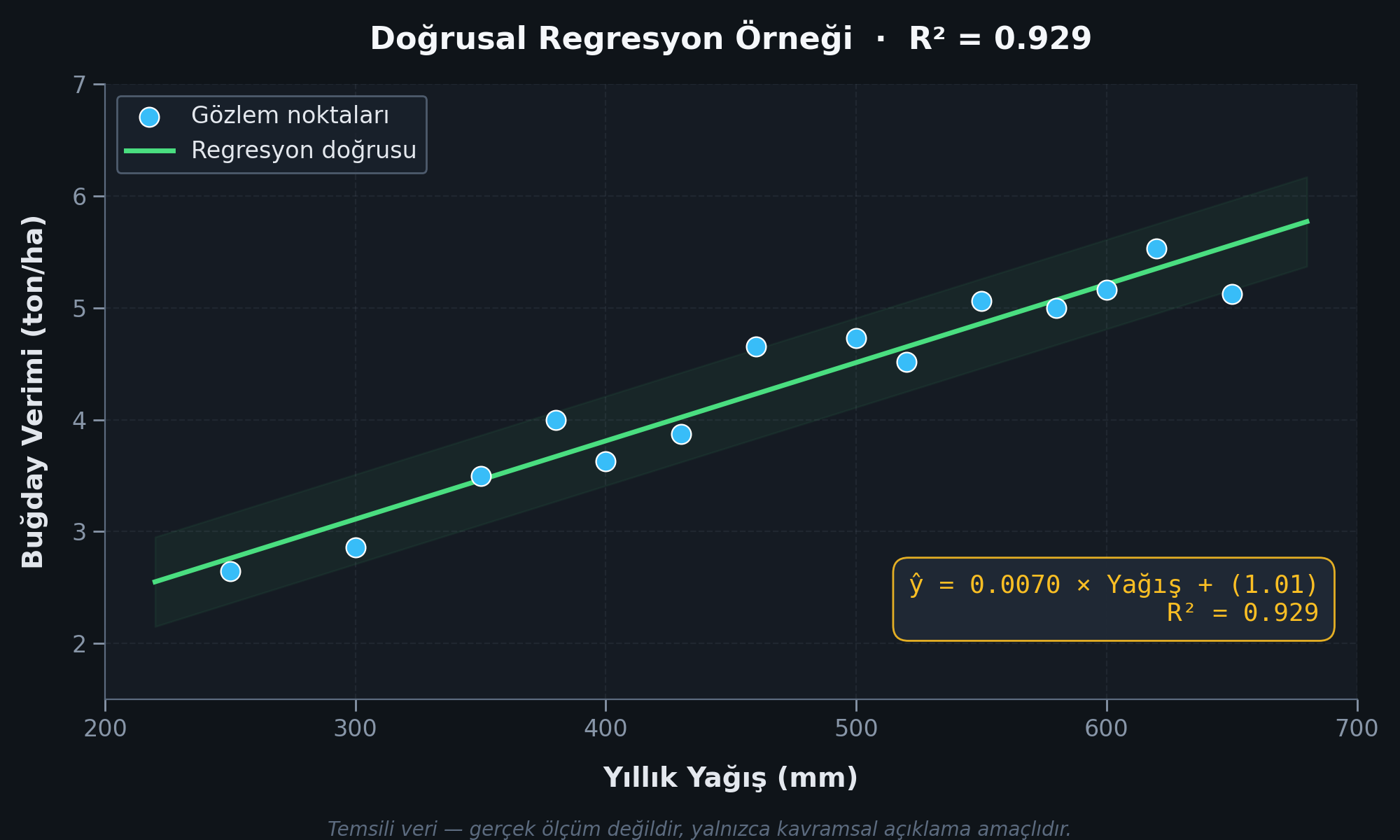
Temsili veri ile doğrusal regresyon örneği. Bu veri gerçek ölçüm değildir; yalnızca kavramsal açıklama amaçlıdır.
Grafiğin yorumu:
- Model denklemi:
Verim = 0.0070 x Yagis + 1.01. Bu, yağış miktarındaki her 100 mm artışın verimde yaklaşık 0.70 ton/ha artışla ilişkili olduğunu ifade eder. - R2 = 0.929: Modelin, verim değişkenliğinin yaklaşık %93'ünü açıkladığını gösterir. Kalan %7 açıklanmayan varyans, modele dahil edilmeyen diğer faktörlere (toprak yapısı, gübre uygulaması, çeşit farklılıkları, sıcaklık vb.) veya ölçüm gürültüsüne atfedilebilir.
- Eğim katsayısı (w = 0.0070): Her değişkenin hedef üzerindeki marjinal etkisini doğrudan gösterir — doğrusal regresyonun yorumlanabilirlik avantajı budur.
- Kesişim (b = 1.01): Yağış sıfır olduğunda bile tahmin edilen verim değeri. Biyolojik açıdan bu değer, kuru koşullarda minimum verim kapasitesi olarak yorumlanabilir; ancak model, eğitim aralığı dışında güvenilir ekstrapolasyon garanti etmez.
Her iki uygulama türünde de model başarısı, etiketlerin kalitesine (uzman doğrulaması, tutarlılık) ve eğitim verisinin temsil gücüne doğrudan bağlıdır.
2.2 Denetimsiz Öğrenme (Unsupervised Learning)
Tanım
Hedef değişken (y) bulunmaksızın, yalnızca girdi verisinin (X) yapısal özelliklerini modellemeye yönelik öğrenme paradigmasıdır. Amaç, veri dağılımındaki örüntüleri, benzerlik ilişkilerini veya sapmaları ortaya çıkarmaktır.
Denetimsiz öğrenmede üç temel problem türü vardır:
- Yapı keşfi (Clustering): Benzer gözlemleri gruplama.
- Temsil öğrenme (Dimensionality Reduction): Veriyi daha düşük boyutlu temsile indirgeme.
- Sapma tespiti (Anomaly Detection): Veri dağılımından belirgin biçimde sapan gözlemleri belirleme.
Neden Gerekli?
Etiketli verinin bulunmadığı veya veri yapısının önceden bilinmediği durumlarda keşifsel analiz sağlar. Ayrıca denetimli öğrenme öncesinde veri yapısını anlamak, gürültüyü azaltmak ve temsil kalitesini iyileştirmek için kullanılır.
Tarımsal Bağlamda Kullanım
Denetimsiz öğrenme, tarımda çoğunlukla veri yapısının keşfi ve karar destek sistemlerinin ön aşaması olarak kullanılır. Aşağıdaki uygulamalar literatürde yaygın biçimde raporlanmıştır.
1. Yönetim Bölgesi Belirleme ve VRA Pipeline'ı
Tarla içi heterojenliği modellemek amacıyla toprak özellikleri (EC, pH, organik madde), çok yıllık verim haritaları ve NDVI verileri üzerinde k-Means veya Fuzzy C-Means kümeleme uygulanır. Elde edilen kümeler, benzer üretim davranışına sahip yönetim bölgelerini tanımlar. Bu bölgeler, bir sonraki aşamada değişken oranlı gübreleme (VRA) ve sulama optimizasyonu gibi uygulamalara doğrudan girdi sağlar. Mekansal gürültüyü temizlemek için DBSCAN yumuşatma adımı eklenebilir.
Bu süreç tek başına bir "uygulama" değil, bir pipeline'dır: Kümeleme → Bölge tanımlama → VRA uygulama. Operasyonel sistemlerde sınırlı fakat artan kullanım alanı bulunmaktadır.
2. Uydu Verisinde Kümeleme Tabanlı Arazi Analizi
Çok bantlı uydu verisinde (Sentinel-2, SAR) piksel vektörleri spektral uzayda kümeleme ile gruplanır. Oluşan kümeler, benzer bitki örtüsü davranışını temsil eder. Bu işlem doğrudan "sınıflandırma" değildir: küme → sınıf eşlemesi sonradan uzman bilgisiyle yapılır (post-labeling). Zaman serisi kümeleme (SITS — Satellite Image Time Series) yaklaşımları, mevsimsel bitki gelişim eğrilerine göre farklı ürün türlerini ayırt edebilmektedir.
3. Sensör Verilerinde Anomali Tespiti
Tarla sensörlerinden gelen zaman serisi verilerinde iki temel denetimsiz anomali tespiti yaklaşımı kullanılır:
- Yoğunluk tabanlı (density-based): Isolation Forest — veri dağılımındaki seyrek bölgeleri anomali olarak işaretler.
- Yeniden yapılandırma tabanlı (reconstruction-based): Autoencoder — normal veriyi sıkıştırıp yeniden oluşturmayı öğrenir; yüksek yeniden yapılandırma hatası anomali göstergesidir.
Her iki yaklaşım da sensör hatası (takılı değer, drift, ani sıçrama) ile gerçek çevresel değişimi ayırt etmeyi amaçlar. Zaman serisi verilerinde gözlemler arası bağımlılık yapısı dikkate alınmalıdır: ardışık gözlemlerde anlık bir sapma ile kademeli bir trend kayması farklı anomali türleridir.
4. Hiperspektral Veride Boyut Azaltma
İHA veya yer tabanlı hiperspektral kameralar 50–200+ bant üretir. PCA uygulanarak bu bantlar, varyansı en çok açıklayan 5–10 temel bileşene indirgenir; hesaplama maliyeti düşer ve gürültü filtrelenir. Ancak PCA bileşenleri fiziksel anlamlılık garanti etmez — yalnızca varyansı optimize eder. Bileşenlerin agronomik yorumlanabilirliği ek analiz gerektirir.
Sınırlar / Hatalı Kullanımlar
- Kümeleme sonuçları benzersiz değildir; başlangıç noktalarına duyarlıdır (k-means++ bu sorunu azaltır).
- Küme sayısı (k) çoğu durumda dışsal olarak belirlenir; elbow ve silhouette yöntemleri rehberlik eder ancak kesin garanti sunmaz.
- Boyut azaltma yöntemleri bilgi kaybına neden olabilir; açıklanan varyans oranı izlenmelidir.
- Anomali tespiti sonuçları, "anomali" tanımına yüksek derecede bağımlıdır; alan bilgisi olmadan yorumlanmamalıdır.
Yöntem Seçimi Bağlamı
| Amaç | Uygun Yöntem | Veri Yapısı Koşulu |
|---|---|---|
| Tarla içi heterojenlik keşfi | k-Means, Fuzzy C-Means | Tablolu, sayısal, düşük-orta boyut |
| Mekansal gürültü temizleme | DBSCAN | Koordinatlı veriler, değişken yoğunluklu kümeler |
| Yüksek boyutlu veri indirgeme | PCA | Korelasyonlu çok sayıda özellik (hiperspektral) |
| Sensör hatası / sapma tespiti | Isolation Forest, Autoencoder | Zaman serisi, etiket yok |
2.3 Pekiştirmeli Öğrenme (Reinforcement Learning)
Tanım
Pekiştirmeli öğrenme, bir ajanın bir çevre ile etkileşerek zaman içinde eylemler seçtiği ve bu eylemler sonucunda elde ettiği ödüller üzerinden bir karar politikası (policy) öğrendiği paradigmadır. Amaç, beklenen kümülatif ödülü maksimize eden politikayı bulmaktır.
Problem genellikle bir Markov Karar Süreci (MDP) ile tanımlanır:
- Durum:
s ∈ S— sistemin anlık durumu - Eylem:
a ∈ A— ajanın alabileceği kararlar - Geçiş:
P(s'|s, a)— eylem sonrası yeni duruma geçiş olasılığı - Ödül:
R(s, a)— anlık geri bildirim
Amaç fonksiyonu: maxπ E[∑t=0∞ γt R(st, at)] — burada γ indirgeme faktörü, uzak gelecekteki ödüllerin bugünkü değerini belirler.
Neden Gerekli?
Denetimli öğrenme statik eşleşmeleri öğrenir (X → y). Pekiştirmeli öğrenme ise zaman bağımlı karar zincirlerini, eylem → sonuç → geri besleme döngüsünü ve uzun vadeli etkileri modelleyebilir. Bu nedenle RL, yalnızca "tahmin" değil, karar verme optimizasyonu problemidir.
Nasıl Çalışır?
Temel bileşenler:
- Policy (π): Durumdan eyleme haritalama — ajan her durumda ne yapacağını politikadan belirler.
- Value function (V, Q): Bir durumun veya durum-eylem çiftinin uzun vadeli beklenen değeri.
- Exploration vs Exploitation: Yeni eylem deneyerek bilgi kazanma ile bilinen iyi eylemi seçerek ödül toplama arasındaki denge.
Yaygın yöntemler:
| Yöntem | Yaklaşım | Özellik |
|---|---|---|
| Q-Learning | Model-free, off-policy | Durum-eylem değer fonksiyonunu öğrenir |
| Policy Gradient | Model-free, on-policy | Politikayı doğrudan optimize eder |
| Actor–Critic | Hibrit | Politika (actor) + değer tahmini (critic) birlikte öğrenir |
Tarımsal Bağlamda Yeri
RL, tarımda doğrudan tahmin problemlerinden ziyade kontrol ve optimizasyon problemlerinde anlamlıdır.
1. Dinamik Sulama Planlaması
- Durum: toprak nemi, hava durumu tahmini, bitki gelişim aşaması
- Eylem: sulama miktarı ve zamanlaması
- Ödül: verim + su verimliliği − maliyet
RL burada kısa vadeli su ihtiyacı ile uzun vadeli verim arasındaki dengeyi öğrenir. Kritik zorluk: ödül fonksiyonunun doğru tanımlanmasıdır — su tasarrufu aşırı optimize edilirse verim düşebilir.
2. Sera İklim Kontrolü
- Durum: sıcaklık, nem, CO2 seviyesi
- Eylem: fan, ısıtıcı, havalandırma ayarları
- Amaç: bitki büyümesini optimize ederken enerji tüketimini minimize etmek
Bu problem, klasik PID kontrolün ötesinde çok değişkenli ve gecikmeli bir sistemdir. RL, değişen dış koşullara adaptif kontrol sağlayabilir.
3. Tarımsal Robotik
- Hasat robotu yol planlama, yabancı ot temizleme rotası optimizasyonu
- RL avantajı: çevre belirsizliği altında karar verebilme
- Sınırlılık: güvenlik ve hata maliyeti çok yüksek — keşif sırasında gerçek ürüne zarar verilebilir
Kritik Sınırlamalar
| Sınırlama | Açıklama | Tarımsal Sonuç |
|---|---|---|
| Veri verimsizliği | RL genellikle milyonlarca etkileşim gerektirir | Gerçek tarlada bu denli deneme mümkün değildir |
| Sim-to-real açığı | Simülasyonda eğitilen politika sahada başarısız olabilir | Toprak, bitki ve hava modelleri gerçeği tam temsil etmez |
| Ödül tasarımı | Yanlış tanımlanmış ödül istenmeyen davranışlara yol açar | Su tasarrufu aşırı optimize edilirse verim düşebilir |
| Stabilite ve güvenlik | Keşif aşamasında zarar verebilir | Tarım sistemleri yavaş dinamikli ve geri dönüşü zordur |
Yöntem Seçimi Bağlamı
| Problem Tipi | RL Uygunluğu |
|---|---|
| Statik tahmin (verim, sınıflandırma) | Uygun değil — denetimli öğrenme tercih edilir |
| Görüntü sınıflandırma | Uygun değil — CNN/denetimli yöntemler tercih edilir |
| Ardışık kontrol (sulama zamanlaması) | Uygun |
| Kapalı döngü optimizasyon (sera kontrolü) | Uygun |
Kısa Kavrama Kontrolü
Yanıt
Denetimli öğrenmede model, her girdi için doğru çıktının (etiketin) doğrudan verildiği veri çiftlerinden öğrenir. Pekiştirmeli öğrenmede ise model, doğru etiketler yerine eylem sonuçlarından gelen gecikmeli ödül sinyalinden öğrenir. Ajan, bir eylemi gerçekleştirdikten sonra bunun iyi mi kötü mü olduğunu ancak zaman geçtikçe — bazen çok sayıda adım sonra — anlayabilir. Bu gecikmeli geri bildirim yapısı (credit assignment problemi), RL'yi denetimli öğrenmeden temelden ayırır ve öğrenmeyi çok daha zorlaştırır.
2.4 Yarı-Denetimli ve Öz-Denetimli Öğrenme
Tanım
Yarı-denetimli öğrenme (Semi-supervised learning): Az sayıda etiketli veri (Xl, yl) ile çok sayıda etiketsiz veri (Xu) birlikte kullanılarak modelin genelleme performansını artırmayı amaçlayan yaklaşımlardır.
Öz-denetimli öğrenme (Self-supervised learning): Etiket gerektirmeden, verinin kendi yapısından türetilen yardımcı görevler (pretext tasks) üzerinden temsil (representation) öğrenmeyi hedefler. Öğrenilen temsil daha sonra denetimli görevlerde kullanılır (pretraining + fine-tuning).
Neden Gerekli?
Makine öğrenmesinde performans çoğunlukla veri miktarına bağlıdır; ancak etiketli veri üretimi pahalıdır (uzman gerektirir), etiketsiz veri ise genellikle bol miktarda mevcuttur. Bu durumda yarı-denetimli öğrenme mevcut az etiketli veriyi güçlendirir; öz-denetimli öğrenme ise veri temsillerini etiket olmadan öğrenir.
Nasıl Çalışır?
1. Yarı-denetimli öğrenme mekanizmaları
Temel varsayım: benzer girdiler benzer çıktılara sahiptir (cluster assumption).
| Yaklaşım | Mekanizma |
|---|---|
| Pseudo-labeling | Model etiketsiz veriye tahmin üretir; yüksek güvenli tahminler "sahte etiket" olarak eğitime dahil edilir |
| Consistency regularization | Aynı girdinin farklı bozunumları (augmentation) altında model çıktısı değişmemelidir |
| Graph-based yöntemler | Veri noktaları arası benzerlik grafı üzerinden etiket yayılımı (label propagation) |
2. Öz-denetimli öğrenme mekanizmaları
Amaç: doğrudan hedef değişkeni değil, verinin anlamlı bir temsil uzayını z = f(x) öğrenmektir.
| Yaklaşım | Mekanizma | Örnekler |
|---|---|---|
| Contrastive learning | Benzer örnekleri yakın, farklıları uzak temsil et | SimCLR, MoCo |
| Masking-based | Verinin bir kısmını gizle ve tahmin et | BERT, MAE |
| Temporal prediction | Zaman serisinde gelecek adımı tahmin et | Zaman serisi ön-eğitim |
Tarımsal Bağlamda Yeri
1. Görüntü verilerinde ön-eğitim: Çok sayıda etiketsiz tarla/drone görüntüsü üzerinde öz-denetimli öğrenme ile temsil öğrenilir, ardından az sayıda etiketli veriyle fine-tuning yapılır. Etiket ihtiyacı önemli ölçüde azalır.
2. Sensör zaman serilerinde temsil öğrenme: Uzun süreli meteorolojik ve toprak verileri üzerinde self-supervised sequence modeling ile mevsimsel ve dinamik yapılar etiket olmadan öğrenilir.
3. Yarı-denetimli hastalık tespiti: Az sayıda etiketli yaprak görüntüsü + çok sayıda etiketsiz görüntü ile pseudo-labeling + fine-tuning uygulanır. Risk: yanlış pseudo-label, modeli bozabilir (hata yayılımı).
Kritik Sınırlamalar
| Sınırlama | Açıklama |
|---|---|
| Varsayım bağımlılığı | Yarı-denetimli öğrenme, cluster assumption ve low-density separation varsayımlarına dayanır; bu varsayımlar sağlanmazsa performans düşer |
| Hata yayılımı | Pseudo-labeling'de yanlış etiketler modele geri beslenir ve hatayı büyütebilir |
| Temsil-görev uyumu | Öz-denetimli öğrenmede öğrenilen temsil, downstream görevle uyumlu olmayabilir |
| Dağılım uyumsuzluğu | Etiketsiz ve etiketli veri farklı dağılımdaysa negatif transfer oluşur |
Yöntem Seçimi Bağlamı
| Durum | Uygun Yaklaşım |
|---|---|
| Bol etiketli veri mevcut | Denetimli öğrenme |
| Etiket yok, yapı keşfi hedefleniyor | Denetimsiz öğrenme |
| Az etiketli + çok etiketsiz veri | Yarı-denetimli öğrenme |
| Çok veri, etiket yok, temsil öğrenme | Öz-denetimli öğrenme |
| Ardışık karar problemi | Pekiştirmeli öğrenme |
Kısa Kavrama Kontrolü
Yanıt
Öz-denetimli öğrenme, veri dağılımını temsil eden anlamlı bir özellik uzayı öğrenir. Pretext görevleri (maskeleme, contrastive karşılaştırma, gelecek adım tahmini) sırasında model, verinin yapısal düzenliliklerini — kenarlar, dokular, mevsimsel kalıplar, mekansal ilişkiler — yakalamak zorunda kalır. Bu temsiller, downstream görevde hedef değişkenle doğrudan ilişkili olacak şekilde tasarlanmamış olsa da, genellikle ham piksellere veya ham sensör değerlerine kıyasla çok daha bilgilendirici bir başlangıç noktası sağlar. Fine-tuning aşamasında model sıfırdan özellik öğrenmek yerine, önceden edinilmiş temsilleri hedefe uyarlar — bu, özellikle etiketli verinin az olduğu durumlarda az örnekle hızlı genelleme (few-shot generalization) kapasitesini artırır.
3. Temel Algoritmalar
3.1 Doğrusal Regresyon (Linear Regression)
Tanım
Doğrusal regresyon, hedef değişkeni girdi değişkenlerinin doğrusal bir kombinasyonu olarak modeller:
y = w1x1 + w2x2 + ... + wpxp + b
Parametreler w ve b, genellikle en küçük kareler (Ordinary Least Squares, OLS) yaklaşımıyla belirlenir:
minw,b ∑i=1n (yi - ŷi)²
OLS kapalı form çözümü: w = (XTX)-1XTy. Büyük veri setleri için gradient descent alternatif olarak kullanılır.
Neden Gerekli?
Doğrusal regresyon üç temel işlev görür:
- Referans model (baseline): Daha karmaşık modellerin gerçekten gerekli olup olmadığını test etmek için karşılaştırma noktası oluşturur.
- Yorumlanabilir içgörü: Her katsayı, ilgili değişkenin hedef üzerindeki marjinal etkisini doğrudan gösterir.
- İlişki analizi: Girdi-çıktı ilişkileri hakkında istatistiksel çıkarım yapmaya imkan tanır.
Özellikle veri ile hedef arasında yaklaşık doğrusal ilişki varsa ve yorumlanabilirlik önemliyse anlamlıdır.
Nasıl Çalışır?
Model, her gözlem için tahmin hatasını (hata = y - ŷ) minimize eder. OLS çözümü hata karelerini minimize eden kapalı form çözüm sağlar.
Katsayıların operasyonel yorumu:
wj = ∂y / ∂xj — diğer değişkenler sabitken xj'deki bir birim artışın y'deki marjinal etkisi.
Temel Varsayımlar
Doğrusal regresyon şu varsayımlara dayanır; ihlal edilirse model tahmini yapılabilir ancak yorumlar güvenilmez olur:
| Varsayım | Açıklama |
|---|---|
| Doğrusallık | y, X'in doğrusal fonksiyonudur |
| Bağımsızlık | Gözlemler birbirinden bağımsızdır |
| Homoskedastisite | Hata varyansı sabittir (tüm x değerlerinde) |
| Normal dağılım | Hatalar normal dağılır (özellikle istatistiksel çıkarım için gerekli) |
Tarımsal Bağlamda Yeri
Doğrusal regresyon genellikle verim tahmini (ilk yaklaşım), girdi-çıktı ilişkisi analizi ve faktör etkisi yorumlama amaçlarıyla kullanılır. Ancak çoğu biyofiziksel süreç (doygunluk, eşik etkisi, etkileşimler) doğrusal değildir; bu nedenle doğrusal model çoğunlukla bir yaklaşım (approximation) olarak değerlendirilmelidir.
Sınırlar / Hatalı Kullanımlar
| Sınırlama | Açıklama | Sonuç |
|---|---|---|
| Doğrusal olmayan ilişkiler | Doygunluk, eşik etkisi, etkileşimler | Model sistematik hata üretir |
| Aykırı değer duyarlılığı | MSE = (y - ŷ)² büyük hataları aşırı cezalandırır | Birkaç outlier tüm modeli bozabilir |
| Multicollinearity | XTX matrisi kötü koşullu veya terslenemez | Katsayılar büyük, kararsız ve yorumlanamaz hale gelir |
| Ekstrapolasyon | Model yalnızca eğitim aralığında güvenilir | Aralık dışında fiziksel olarak anlamsız sonuçlar üretebilir |
Ne Zaman Kullanılır / Kullanılmaz
| Kullanılır | Kullanılmaz |
|---|---|
| Küçük-orta veri seti | Güçlü nonlinearity varsa |
| Yorumlanabilirlik önemli | Feature interaction önemliyse |
| Yaklaşık doğrusal ilişki | Yüksek boyut + korelasyon varsa |
Alternatifler
| Problem | Alternatif |
|---|---|
| Nonlinearity | Polinom regresyon, ağaç tabanlı modeller |
| Multicollinearity | Ridge (L2), Lasso (L1) |
| Outlier | Robust regresyon (Huber, RANSAC) |
| Kompleks yapı | Random Forest, Gradient Boosting |
Özellik Tablosu
| Özellik | Değer |
|---|---|
| Problem türü | Regresyon |
| Uygun veri yapısı | Tablolu, sayısal özellikler |
| Güçlü yönler | Yorumlanabilirlik, hesaplama hızı, baseline olarak kullanım |
| Başlıca sınırlar | Nonlinearity, aykırı değer hassasiyeti, multicollinearity |
| Yorumlanabilirlik | Yüksek |
Kısa Kavrama Kontrolü
Yanıt
Multicollinearity durumunda bağımsız değişkenler birbirine bağımlıdır (yüksek korelasyon). Bu durumda XTX matrisi kötü koşullu hale gelir ve katsayı tahminleri yüksek varyansa sahip olur — küçük veri değişiklikleri katsayılarda büyük dalgalanmalara yol açar. Model, her değişkenin hedef üzerindeki bağımsız etkisini ayrıştıramaz çünkü korelasyonlu değişkenlerin etkileri iç içe geçmiştir. Sonuç: model toplamda makul tahmin üretebilir (tahmin performansı korunabilir), ancak bireysel katsayıların "xj bir birim artarsa y şu kadar artar" biçiminde yorumlanması yanıltıcı olur. Ridge regresyon (L2 düzenleme) bu sorunu katsayıları küçülterek hafifletir.
3.2 Lojistik Regresyon (Logistic Regression)
Tanım
Lojistik regresyon, adına rağmen bir sınıflandırma yöntemidir. Doğrusal bir skor üretir ve bu skoru lojistik (sigmoid) fonksiyon ile olasılığa dönüştürür:
P(y=1|X) = σ(z) = 1 / (1 + e-z), z = wTX + b
Karar kuralı: ŷ = 1 [P(y=1|X) ≥ τ] — burada τ karar eşiğidir (varsayılan 0.5).
Amaç Fonksiyonu
Parametreler log-loss (binary cross-entropy) minimize edilerek öğrenilir:
minw,b -∑i=1n [yi log pi + (1-yi) log(1-pi)]
Bu, maksimum olabilirlik (MLE) ile eşdeğerdir ve Bernoulli dağılımı varsayımına dayanır. Kayıp fonksiyonu konvekstir — global optimum garantisi sağlar.
Olasılık ve Yorum
Model, log-odds (logit) değerini doğrusal olarak modeller:
log(p / (1-p)) = wTX + b
- wj: xj'deki bir birim artışın log-odds üzerindeki marjinal etkisi.
- ewj: Odds ratio — yorumlanabilirlik için kritik. "xj bir birim artarsa pozitif sınıfa ait olma odds'u ewj kat değişir."
Neden Gerekli?
- Olasılık çıktısı: Karar eşiği (τ) probleme göre ayarlanabilir.
- Yorumlanabilirlik: Odds ratio aracılığıyla her değişkenin etkisi yorumlanabilir.
- Konveks optimizasyon: Global optimum garantisi — yerel minimuma takılma riski yoktur.
- Güçlü baseline: Küçük-orta veri setlerinde daha karmaşık modellerin gerekli olup olmadığını test etmek için referans.
Operasyonel Kullanım
Karar eşiği ayarı: Varsayılan τ = 0.5 her zaman optimal değildir. Maliyet duyarlı problemlerde yanlış negatif maliyeti yüksekse τ düşürülür (daha fazla pozitif tahmin); yanlış pozitif maliyeti yüksekse τ artırılır.
Düzenlileştirme: Multicollinearity ve overfitting için kayıp fonksiyonuna ceza terimi eklenir:
+ λ||w||1(L1) → sparsity, özellik seçimi+ λ||w||22(L2) → katsayı stabilizasyonu
Özellik ölçekleme: Gradient tabanlı optimizasyon için önemlidir; özellikle L1/L2 düzenleme kullanılıyorsa kritiktir.
Çok sınıflı genişleme: One-vs-Rest (OvR) veya Softmax (multinomial logistic regression) ile çok sınıflı problemlere genişletilebilir:
P(y=k|X) = ewkTX / ∑j ewjTX
Tarımsal Bağlamda Yeri
Tipik kullanım alanları: hastalık var/yok tespiti, zararlı varlığı (presence/absence), sulama ihtiyacı (ikili karar). Karar sınırı + olasılık birlikte sağlanması, tarımsal karar destek sistemlerinde eşik ayarına olanak tanır. Ancak çoğu biyolojik süreç doğrusal olarak ayrılabilir olmadığından, karmaşık problemlerde yetersiz kalabilir.
Sınırlar / Hatalı Kullanımlar
| Sınırlama | Açıklama |
|---|---|
| Doğrusal karar sınırı | Karar sınırı wTX + b = 0 bir lineer hiper-düzlemdir. Nonlinearity varsa model sistematik hata üretir. |
| Özellik etkileşimleri | Varsayılan olarak feature interaction öğrenmez; manuel feature engineering gerekir. |
| Complete separation | Veri tamamen doğrusal ayrılabiliyorsa katsayılar → ∞, çözüm kararsızlaşır. |
| Kalibrasyon | Teorik olarak olasılık üretir; pratikte kalibrasyon hatası olabilir (Platt scaling / isotonic regression gerekebilir). |
| Dengesiz veri | Model çoğunluk sınıfına kayabilir. Çözüm: class weighting veya threshold tuning. |
Ne Zaman Kullanılır / Kullanılmaz
| Kullanılır | Kullanılmaz |
|---|---|
| Yorumlanabilirlik önemli | Karmaşık nonlinearity |
| Veri yaklaşık doğrusal ayrılabilir | Yüksek feature interaction |
| Küçük-orta veri seti | Görüntü / ham sinyal verisi |
Özellik Tablosu
| Özellik | Değer |
|---|---|
| Problem türü | Sınıflandırma (ikili; Softmax ile çok sınıflıya genişletilebilir) |
| Çıktı | Olasılık [0, 1] |
| Optimizasyon | Log-loss (MLE), konveks |
| Güçlü yönler | Yorumlanabilirlik (odds ratio), hız, olasılık çıktısı |
| Başlıca sınırlar | Doğrusal karar sınırı, feature interaction eksikliği |
| Yorumlanabilirlik | Yüksek |
Kısa Kavrama Kontrolü
Yanıt
Log-odds dönüşümü iki kritik avantaj sağlar: (1) Olasılık [0, 1] aralığında sınırlıyken, log-odds (-∞, +∞) aralığında tanımlıdır. Bu, doğrusal modelin sınırsız çıktısı ile olasılığın sınırlı aralığı arasında uyum sağlar — sigmoid fonksiyonu bu eşlemeyi gerçekleştirir. (2) Kayıp fonksiyonu (log-loss) parametrelere göre konveks kalır, bu da gradient tabanlı optimizasyonun global optimuma yakınsamasını garanti eder. Eğer olasılık doğrudan doğrusal olarak modellenmeye çalışılsaydı, tahminler [0, 1] aralığı dışına çıkabilir ve optimizasyon konveksliğini kaybedebilirdi.
3.3 k-En Yakın Komşu (k-NN)
Tanım
k-NN, parametrik olmayan ve lazy learning yaklaşımına sahip bir yöntemdir. Eğitim aşamasında açık bir model öğrenmez; tahmin aşamasında yeni bir gözlem için veri setindeki en yakın k komşuya bakarak karar verir.
- Sınıflandırma:
ŷ = mode(y(1), ..., y(k))— çoğunluk oyu - Regresyon:
ŷ = (1/k) ∑i=1k y(i)— ortalama (veya mesafeye göre ağırlıklı ortalama:wi = 1/d(x, xi))
Nasıl Çalışır?
Verilen bir x için: (1) tüm eğitim örnekleri ile mesafe hesaplanır, (2) en küçük mesafeye sahip k örnek seçilir, (3) seçilen komşuların etiketlerine göre tahmin üretilir.
Mesafe metrikleri — seçilen metrik modelin davranışını doğrudan belirler:
| Metrik | Formül | Uygun Durum |
|---|---|---|
| Öklid (L2) | (∑|xi - x'i|2)1/2 | Sürekli ve izotropik veri |
| Manhattan (L1) | ∑|xi - x'i| | Aykırı değerlere daha dayanıklı |
| Minkowski | (∑|xi - x'i|p)1/p | Genel form (p=1: Manhattan, p=2: Öklid) |
| Hamming | Farklı konumların sayısı | Kategorik veri |
Neden Gerekli?
- Model varsayımı yok — esnek karar sınırı, nonlinearity'yi doğal olarak yakalar.
- Küçük veri setlerinde güçlü baseline.
- Lokal yapıların korunması — verinin yerel komşuluk yapısını doğrudan kullanır.
Operasyonel Parametreler
1. k seçimi: Küçük k → düşük bias, yüksek varyans (gürültüye duyarlı). Büyük k → yüksek bias, düşük varyans (aşırı yumuşatma). Tipik olarak çapraz doğrulama ile belirlenir.
2. Ölçekleme (zorunlu): Mesafe temelli olduğu için x' = (x - μ) / σ standardizasyonu uygulanmalıdır. Aksi halde büyük ölçekli değişkenler mesafeyi domine eder.
3. Özellik seçimi: İlgisiz özellikler mesafeyi bozarak performansı düşürür. Boyut azaltma (PCA) veya özellik seçimi ön adım olarak değerlendirilmelidir.
Tarımsal Bağlamda Yeri
Tipik kullanım: benzer tarla koşullarına göre verim tahmini, hastalık benzerlik tabanlı sınıflandırma, sensör verisinde pattern matching. Lokal benzerlik üzerinden karar verir ve fiziksel model gerektirmez.
Sınırlar / Hatalı Kullanımlar
| Sınırlama | Açıklama | Sonuç |
|---|---|---|
| Boyut laneti | Boyut arttıkça mesafeler uniform dağılıma yaklaşır | Yakın/uzak farkı kaybolur, model anlamsızlaşır |
| Hesaplama maliyeti | Tahmin zamanında O(n · d) | Büyük veri setlerinde pratik değil |
| Bellek kullanımı | Tüm eğitim verisi bellekte tutulur | Memory-bound |
| Gürültü duyarlılığı | Aykırı değerler komşu setine girerse | Tahmin bozulur |
| Seyrek bölgeler | Veri yoğunluğu düşük bölgelerde | Yanlış komşular seçilir |
Hızlandırma Yöntemleri
Büyük veri setleri için: KD-Tree, Ball Tree, Approximate Nearest Neighbor (FAISS, Annoy). Ancak yüksek boyutta bu yapılar da etkisini kaybeder.
Ne Zaman Kullanılır / Kullanılmaz
| Kullanılır | Kullanılmaz |
|---|---|
| Düşük boyut (<20-30 özellik) | Yüksek boyutlu veri |
| Küçük veri seti | Büyük veri seti (>100K) |
| Lokal yapı önemli | Gerçek zamanlı sistemler |
Özellik Tablosu
| Özellik | Değer |
|---|---|
| Problem türü | Sınıflandırma, regresyon |
| Model tipi | Parametrik olmayan |
| Öğrenme | Lazy (tembel) |
| Güçlü yönler | Esneklik, basitlik, lokal yapı korunması |
| Başlıca sınırlar | Boyut laneti, hesaplama maliyeti, ölçekleme zorunluluğu |
| Yorumlanabilirlik | Orta (komşu bazında açıklanabilir) |
Kısa Kavrama Kontrolü
Yanıt
Büyük sayısal aralığa sahip değişkenler (örn. yağış: 0-150 mm) mesafe hesaplamasını domine eder; dar aralıklı değişkenler (örn. pH: 4-9) mesafe üzerinde neredeyse hiç etkili olamaz. Sonuç olarak model, gerçekte önemli olan değişkenleri görmezden gelerek yalnızca büyük ölçekli değişkenlere göre komşu seçer — bu da hem sınıflandırma hem regresyon performansını sistematik olarak düşürür. Çözüm: Z-score standardizasyonu veya Min-Max normalizasyonu uygulamak. Ölçekleme parametreleri yalnızca eğitim setinden türetilmelidir.
3.4 Karar Ağaçları ve Rastgele Orman
Tanım
Karar ağaçları (Decision Trees), veriyi özellik uzayında ardışık bölünmelerle parçalayan hiyerarşik modellerdir. Her düğümde bir özellik ve eşik seçilir (xj ≤ t); bölünmeler sonucunda veri alt kümelere ayrılır ve yaprak düğümlerde tahmin yapılır.
Bölünme kriterleri:
| Problem | Kriter | Formül |
|---|---|---|
| Sınıflandırma | Gini impurity | G = 1 - ∑pk2 |
| Sınıflandırma | Entropy | H = -∑pk log pk |
| Regresyon | Varyans minimizasyonu | min ∑(yi - ȳ)2 |
Rastgele Orman (Random Forest), birden fazla karar ağacının birleşimidir:
- Bootstrap sampling: Her ağaç farklı veri alt kümesiyle eğitilir.
- Feature subsampling: Her bölünmede rastgele özellik alt kümesi seçilir.
- Aggregation: Sınıflandırmada çoğunluk oyu, regresyonda ortalama.
Neden Gerekli?
Karar ağacının temel problemi: düşük bias ancak çok yüksek varyans (overfitting). Random Forest çözümü: farklı veri alt kümeleriyle eğitilmiş ağaçların ortalaması varyansı azaltır. Bias biraz artar, ancak genel performans iyileşir.
Operasyonel Özellikler
- Nonlinearity: Ağaçlar doğrusal olmayan ilişkileri doğal olarak yakalar.
- Feature interaction: Manuel feature engineering gerekmez; model etkileşimleri otomatik öğrenir.
- Ölçekleme: Gerekmez — mesafe tabanlı değildir, bölünme kararları sıralı karşılaştırmaya dayanır.
Özellik Önemi (Feature Importance)
Random Forest iki tür önem ölçüsü sağlar:
- Impurity decrease: Her özelliğin bölünme kararlarındaki toplam impurity azalması.
- Permutation importance: Özellik değerleri karıştırıldığında performans düşüşü.
Tarımsal Bağlamda Yeri
Tipik kullanım: tablolu sensör/iklim verilerinden verim tahmini, toprak özelliklerinden sınıflandırma, uzaktan algılama verilerinde piksel sınıflandırma. Heterojen ve gürültülü tarımsal veride robust performans sağlar.
Sınırlar / Hatalı Kullanımlar
| Sınırlama | Açıklama |
|---|---|
| Overfitting (tek ağaç) | Budama yapılmazsa eğitim verisini ezberler |
| Ekstrapolasyon yok | Ağaçlar gözlenen değer aralıkları içinde tahmin yapar; aralık dışına genelleme yapamaz |
| Model boyutu | Yüzlerce ağaç → büyük bellek tüketimi |
| Yorumlanabilirlik kaybı | Tek ağaç yorumlanabilir; orman opaklaşır |
| Dengesiz veri | Çoğunluk sınıfa kayma → class weighting gerekir |
Ne Zaman Kullanılır / Kullanılmaz
| Kullanılır | Kullanılmaz |
|---|---|
| Tablolu veri | Çok yüksek boyut + seyrek veri |
| Nonlinearity + feature interaction | Zaman serisi bağımlılığı yüksekse (özel model gerekir) |
| Hızlı ve güçlü baseline | Ekstrapolasyon gerekiyorsa |
Özellik Tablosu
| Özellik | Karar Ağacı | Rastgele Orman |
|---|---|---|
| Problem türü | Sınıflandırma, regresyon | Sınıflandırma, regresyon |
| Model tipi | Tek model | Ensemble |
| Bias | Düşük | Orta |
| Varyans | Yüksek | Düşük |
| Güçlü yönler | Yorumlanabilirlik, hız | Genelleme, robustluk |
| Başlıca sınırlar | Overfitting | Ekstrapolasyon yok |
| Yorumlanabilirlik | Yüksek | Orta |
Kısa Kavrama Kontrolü
Yanıt
Tek bir karar ağacı düşük bias ancak yüksek varyansa sahiptir — eğitim verisindeki gürültüye aşırı uyum gösterir ve farklı veri alt kümeleriyle eğitildiğinde çok farklı yapılar üretir. Random Forest, bu sorunu iki mekanizma ile çözer: (1) Bootstrap sampling: Her ağaç farklı bir veri alt kümesiyle eğitilir, böylece ağaçlar arasında çeşitlilik sağlanır. (2) Feature subsampling: Her bölünmede rastgele seçilen özellik alt kümesi kullanılır, bu da ağaçların birbirine korelasyonunu azaltır. Bağımsız ve düşük korelasyonlu tahminlerin ortalaması, bireysel tahminlerin varyansını azaltır (varyans azaltma ilkesi). Sonuç: bias biraz artar, ancak varyans büyük ölçüde düşer ve genel genelleme performansı iyileşir.
3.5 Destek Vektör Makineleri (SVM)
Tanım
SVM, sınıflar arasında maksimum marjı sağlayan bir karar hiper-düzlemi bulan yöntemdir. Doğrusal durumda karar fonksiyonu:
f(x) = wTx + b
Optimizasyon Problemi
Soft-margin SVM formülasyonu:
minw,b,ξ (1/2)||w||2 + C ∑ξi
Kısıtlar: yi(wTxi + b) ≥ 1 - ξi
||w||→ marjı belirler (küçük norm = geniş marj)ξi→ slack değişkeni (hata toleransı)C→ marj genişliği ile hata toleransı arasındaki denge
Hinge loss yorumu: max(0, 1 - y·f(x)) — yanlış sınıflandırılan ve marja yakın noktalar cezalandırılır; doğru ve uzak noktalar etkisizdir.
Kernel Trick
Doğrusal ayrım mümkün değilse, veri yüksek boyutlu uzaya açıkça taşınmadan kernel fonksiyonu ile inner product hesaplanır:
K(x, x') = φ(x)Tφ(x')
| Kernel | Formül | Uygun Durum |
|---|---|---|
| Linear | xTx' | Doğrusal ayrılabilir veri |
| Polynomial | (xTx' + c)d | Özellik etkileşimleri |
| RBF (Gaussian) | e-γ||x-x'||2 | Genel amaçlı, nonlinear |
Hiperparametreler
| Parametre | Etkisi |
|---|---|
| C (regularization) | Büyük C → düşük bias, yüksek varyans (dar marj, az hata toleransı). Küçük C → geniş marj, daha fazla hata toleransı. |
| γ (RBF kernel) | Büyük γ → lokal, karmaşık karar sınırı. Küçük γ → daha düzgün (smooth) sınır. |
Neden Gerekli?
- Yüksek boyutta (p >> n) iyi çalışır.
- Marj maksimizasyonu genelleme avantajı sağlar.
- Karar yalnızca destek vektörlerine bağlıdır — sparsity:
f(x) = ∑αi K(xi, x) + b
Operasyonel Özellikler
Ölçekleme zorunludur: SVM mesafe/kernel tabanlıdır. x' = (x - μ) / σ standardizasyonu yapılmazsa kernel hesaplamaları bozulur.
Tarımsal Bağlamda Yeri
Tipik kullanım: hiperspektral veri sınıflandırma, bitki hastalığı tespiti, uzaktan algılama (yüksek boyut, az örnek). Az veri + yüksek boyut kombinasyonunda güçlü performans sağlar.
Sınırlar / Hatalı Kullanımlar
| Sınırlama | Açıklama |
|---|---|
| Ölçeklenme | Eğitim karmaşıklığı O(n2) – O(n3); büyük veri için uygun değil |
| Hiperparametre hassasiyeti | Yanlış kernel / C / γ seçimi ciddi performans düşüşüne yol açar |
| Olasılık çıktısı yok | Doğal çıktı margin'dir; olasılık için Platt scaling gerekir |
| Yorumlanabilirlik | Linear SVM kısmen yorumlanabilir; kernel SVM opaktır |
| Gürültü duyarlılığı | Yanlış etiketli veri destek vektörü olabilir ve modeli bozar |
Ne Zaman Kullanılır / Kullanılmaz
| Kullanılır | Kullanılmaz |
|---|---|
| Küçük-orta veri seti | Çok büyük veri (>100K) |
| Yüksek boyut (hiperspektral, görüntü özellikleri) | Çok gürültülü veri |
| Güçlü sınır ayrımı varsa | Hızlı inference gerektiren sistemler |
Özellik Tablosu
| Özellik | Değer |
|---|---|
| Problem türü | Sınıflandırma, regresyon (SVR) |
| Model tipi | Margin-based |
| Optimizasyon | Hinge loss + regularization |
| Güçlü yönler | Yüksek boyutta performans, marj maksimizasyonu |
| Başlıca sınırlar | Ölçeklenme, parametre hassasiyeti |
| Yorumlanabilirlik | Düşük (kernel kullanıldığında) |
Kısa Kavrama Kontrolü
Yanıt
C artırıldığında model, eğitim verisindeki hataları daha ağır cezalandırır. Slack değişkenlerine (ξ) izin verilen alan daralır; bu da karar sınırının eğitim noktalarına daha yakın geçmesine (dar marj) ve daha az hata toleransına yol açar. Sonuç: düşük bias (eğitim verisine daha iyi uyum) ancak yüksek varyans (overfitting riski artar). Tersine, C küçültüldüğünde model daha geniş marj tercih eder, bazı eğitim hatalarına tolerans gösterir ve daha iyi genelleme yapabilir. C seçimi tipik olarak çapraz doğrulama ile belirlenir.
3.6 Naive Bayes
Tanım
Naive Bayes, Bayes teoremine dayalı bir sınıflandırıcıdır:
P(y|X) ∝ P(y) ∏j=1p P(xj|y)
Temel varsayım: özellikler, sınıf verildiğinde koşullu bağımsızdır. Bu varsayım pratikte nadiren karşılansa da yüksek boyutlu seyrek verilerde rekabetçi sonuçlar üretebilir.
Nasıl Çalışır?
Karar kuralı (sayısal stabilite için log formunda):
ŷ = argmaxy [log P(y) + ∑j log P(xj|y)]
Varyantlar:
| Varyant | Veri Türü | Dağılım Varsayımı |
|---|---|---|
| Gaussian NB | Sürekli veri | Normal dağılım |
| Multinomial NB | Sayım verisi (metin, frekans) | Multinomial dağılım |
| Bernoulli NB | Binary özellikler | Bernoulli dağılım |
Neden Gerekli?
- Yüksek boyutlu veri (p >> n) ile çalışabilir.
- Eğitim ve tahmin çok hızlıdır.
- Az veri ile makul performans sağlayabilir.
Tarımsal Bağlamda Yeri
Hastalık var/yok (basit ikili sınıflandırma), sensör threshold tabanlı ayrımlar, düşük veri + hızlı karar gereken sistemlerde kullanılabilir.
Sınırlar / Hatalı Kullanımlar
| Sınırlama | Açıklama |
|---|---|
| Bağımsızlık varsayımı | Gerçekte P(xi, xj|y) ≠ P(xi|y)P(xj|y). Model yanlış olasılık üretir; ancak sınıflandırma sıralaması yine doğru olabilir. |
| Kalibrasyon | Çoğu zaman aşırı kendinden emin (overconfident) tahmin üretir. |
| Dağılım varsayımı | Gaussian NB normal dağılım varsayar; gerçek veri çoğu zaman bu varsayıma uymaz. |
| Sıfır olasılık | P(xj|y) = 0 ise P(y|X) = 0 olur. Çözüm: Laplace smoothing. |
Ne Zaman Kullanılır / Kullanılmaz
| Kullanılır | Kullanılmaz |
|---|---|
| Yüksek boyutlu veri | Güçlü feature korelasyonu |
| Hızlı baseline | Hassas olasılık kalibrasyonu gerekiyorsa |
| Düşük veri miktarı | Karmaşık etkileşimli yapılar |
Özellik Tablosu
| Özellik | Değer |
|---|---|
| Problem türü | Sınıflandırma |
| Model tipi | Olasılıksal |
| Temel varsayım | Koşullu bağımsızlık |
| Güçlü yönler | Hız, sadelik, az veri ile çalışabilme |
| Başlıca sınırlar | Varsayım ihlali, kalibrasyon hatası |
| Yorumlanabilirlik | Orta |
3.7 k-Means Kümeleme
Tanım
k-Means, veriyi k kümeye ayıran ve her kümenin merkezini minimize eden denetimsiz bir algoritmadır.
Amaç fonksiyonu:
min ∑i=1k ∑x∈Ci ||x - μi||2
→ küme içi varyansı minimize eder.
Nasıl Çalışır?
- k merkez başlatılır.
- Her nokta en yakın merkeze atanır.
- Merkezler güncellenir:
μi = (1/|Ci|) ∑x - Yakınsama → atamalar değişmeyene kadar tekrarlanır.
Yakınsama özelliği: Her iterasyonda amaç fonksiyonu azalır; ancak global optimum garantisi yoktur — lokal minimuma takılabilir.
Neden Gerekli?
- Veri yapısını keşfetmek (keşifsel analiz)
- Segmentasyon ve gruplama
- Ön işleme aşamasında özellik üretimi
Tarımsal Bağlamda Yeri
Tarla içi bölgeleme (management zones), uydu piksel segmentasyonu, sensör pattern gruplama.
Sınırlar / Hatalı Kullanımlar
| Sınırlama | Açıklama |
|---|---|
| k seçimi | Dışsal parametre; elbow / silhouette yöntemleri heuristiktir |
| Küme şekli varsayımı | Küresel ve eş yoğunluklu kümeler varsayar; gerçekte çoğunlukla sağlanmaz |
| Ölçekleme zorunlu | Mesafe tabanlı olduğu için standardizasyon gerekir |
| Başlatma duyarlılığı | Farklı başlangıç → farklı sonuç; k-means++ ile hafifletilir |
| Outlier etkisi | Ortalama tabanlı olduğundan aykırı değerler merkezleri kaydırır |
Alternatifler
| Problem | Alternatif |
|---|---|
| Farklı yoğunluklu kümeler | DBSCAN |
| Eliptik küme yapısı | Gaussian Mixture Model |
| Outlier varlığı | DBSCAN |
Özellik Tablosu
| Özellik | Değer |
|---|---|
| Problem türü | Kümeleme (denetimsiz) |
| Model tipi | Distance-based |
| Amaç | Küme içi varyans minimizasyonu |
| Güçlü yönler | Basitlik, hız, ölçeklenebilirlik |
| Başlıca sınırlar | k seçimi, şekil varsayımı, outlier duyarlılığı |
| Yorumlanabilirlik | Orta |
Kısa Kavrama Kontrolü
Yanıt
Birkaç olası açıklama vardır: (1) k fazla seçilmiş olabilir: Verinin doğal yapısı 2 kümeye daha uygunken k=3 zorlaması, bir kümenin yapay biçimde bölünmesine yol açabilir. (2) Veri doğal olarak dengesiz kümelere sahip olabilir: Gerçek yapıda bir grup çok küçükse bu normal bir sonuçtur. (3) Küçük küme outlier grubu olabilir: Aykırı gözlemler ana kümelerden uzakta ayrı bir küme oluşturmuş olabilir — alan bilgisiyle değerlendirilmelidir. (4) Veri yoğunluğu heterojendir: Farklı yoğunluklardaki kümeler k-Means'in küresel ve eş yoğunluk varsayımına uymaz; DBSCAN gibi yoğunluk tabanlı yöntemler daha uygun olabilir. Elbow yöntemi ve silhouette analizi ile farklı k değerleri karşılaştırılmalıdır.
4. Model Değerlendirme
4.1 Kayıp Fonksiyonları (Loss Functions)
Tanım
Modelin tahminleri ile gerçek değerler arasındaki uyumsuzluğu ölçen fonksiyonlardır. Eğitim sürecinde model, kayıp fonksiyonunu minimize etmeye çalışır.
- MSE (Mean Squared Error): Regresyon için standart kayıp. Büyük hatalara karesel ceza uyguladığından aykırı değerlere duyarlıdır.
- Cross-Entropy (Çapraz Entropi): Sınıflandırma için standart kayıp. Modelin tahmin ettiği olasılık dağılımı ile gerçek etiket dağılımı arasındaki farklılığı ölçer.
4.2 Sınıflandırma Metrikleri
Tanım ve Bağlam
Tek başına doğruluk (accuracy) metriği, sınıf dağılımı dengesiz olduğunda yanıltıcı sonuçlar üretebilir. Bir veri setinde gözlemlerin %95'i tek bir sınıfa aitse, sabit olarak çoğunluk sınıfını tahmin eden bir model %95 doğruluk elde eder; ancak azınlık sınıfını hiç tespit edemez.
| Metrik | Tanım | Tercih Koşulu |
|---|---|---|
| Doğruluk (Accuracy) | Doğru tahminlerin toplam gözlemlere oranı | Sınıf dağılımı yaklaşık dengeli olduğunda |
| Kesinlik (Precision) | TP / (TP + FP) | Yanlış pozitif maliyetinin yüksek olduğu durumlar |
| Duyarlılık (Recall) | TP / (TP + FN) | Yanlış negatif maliyetinin yüksek olduğu durumlar |
| F1-Skoru | Kesinlik ve duyarlılığın harmonik ortalaması | Dengesiz sınıflarda veya her iki hata türü de önemli olduğunda |
4.3 Karmaşıklık Matrisi (Confusion Matrix)
Tanım
Sınıflandırma sonuçlarını gerçek ve tahmin edilen etiketlerin çapraz tablosu olarak özetleyen yapıdır. Doğru pozitif (TP), yanlış pozitif (FP), doğru negatif (TN) ve yanlış negatif (FN) değerlerini bir arada sunar. Yukarıdaki tüm metrikler bu dört bileşenden türetilir.
4.4 Çapraz Doğrulama (Cross-Validation)
Tanım
Veri setini k eşit katmana (fold) bölerek, her katmanın sırayla test seti olarak kullanıldığı, geri kalan k−1 katmanın eğitim seti oluşturduğu bir değerlendirme stratejisidir. Sonuç, k farklı performans ölçümünün ortalama ve standart sapmasıdır.
Neden Gerekli?
Tek bir eğitim-test bölünmesine dayanan tahminler, bölünmenin rastgeleliğine bağlı olarak yüksek varyans gösterebilir. Çapraz doğrulama, performans tahmininin güvenilirliğini artırır ve özellikle küçük veri setlerinde tercih edilir.
Sınırlar / Hatalı Kullanımlar
- Zamansal bağımlılık taşıyan verilerde standart k-fold uygulaması zamansal sızıntıya yol açar; zaman serisi bölünme stratejileri (time series split) kullanılmalıdır.
- Mekansal bağımlılık taşıyan verilerde (örn. coğrafi olarak yakın noktalar) mekânsal çapraz doğrulama (spatial CV) gerekebilir.
4.5 ROC Eğrisi ve AUC
Tanım
ROC (Receiver Operating Characteristic) eğrisi, farklı karar eşiklerinde duyarlılık (TPR) ile yanlış pozitif oranını (FPR) karşılaştırır. AUC (Area Under the Curve), bu eğrinin altında kalan alandır. AUC = 1.0 mükemmel ayrım, AUC = 0.5 rastgele tahmin düzeyinde performans anlamına gelir.
Sınırlar / Hatalı Kullanımlar
- Çok dengesiz sınıf dağılımında AUC iyimser sonuçlar üretebilir; Precision-Recall eğrisi (PR-AUC) daha bilgilendirici olabilir.
Kısa Kavrama Kontrolü
Yanıt
Yüksek kesinlik, düşük duyarlılık şu anlama gelir: model "pozitif" dediğinde büyük olasılıkla haklıdır, ancak gerçek pozitiflerin önemli bir kısmını kaçırır. Model temkinli davranır — emin olmadığında "negatif" der. Kabul edilebilir olduğu durumlar: Yanlış pozitifin maliyetinin yüksek olduğu uygulamalar. Örneğin pahalı bir pestisit uygulaması kararında yanlış alarm doğrudan ekonomik kayıp demektir; bu durumda modelin yalnızca emin olduğunda "uygula" demesi tercih edilebilir. Sorunlu olduğu durumlar: Kaçırmanın maliyetinin yüksek olduğu uygulamalar. Bulaşıcı bir bitki hastalığının erken tespitinde düşük recall, hastalıklı bitkilerin tespit edilememesi ve salgının yayılması anlamına gelir. Bu tür problemlerde recall öncelikli olmalı, gerekirse daha fazla yanlış alarm kabul edilmelidir. Precision-recall dengesi, karar eşiğinin ayarlanmasıyla probleme özgü biçimde kalibre edilebilir.
5. Aşırı Öğrenme ve Düzenleme
5.1 Bias-Variance Dengesi
Tanım
Modelin toplam hatasının iki bileşeni vardır:
- Yanlılık (Bias): Modelin sistematik hatası. Yüksek bias, modelin veri yapısını yeterince yakalayamadığını gösterir (underfitting).
- Varyans (Variance): Modelin eğitim verisi değiştiğinde tahminlerindeki dalgalanma. Yüksek varyans, eğitim verisine aşırı uyumu (overfitting) işaret eder.
Bu iki bileşen genellikle ters orantılıdır; model karmaşıklığı arttıkça bias azalır, varyans artar.
5.2 Overfitting ve Underfitting
Tanım
Overfitting: Model, eğitim verisindeki gürültü dahil tüm yapıyı ezberler; yeni veriye genelleyemez. Belirtisi: eğitim hatası düşük, test hatası yüksek.
Underfitting: Model, verideki temel yapıyı dahi öğrenemeyecek kadar basittir. Belirtisi: hem eğitim hem test hatası yüksek.
5.3 Düzenleme (Regularization)
Tanım
Modelin karmaşıklığına ceza uygulayarak aşırı öğrenmeyi engellemeye yönelik tekniklerdir.
- L1 (Lasso): Kayıp fonksiyonuna katsayıların mutlak değerlerinin toplamını ekler. Bazı katsayıları tam sıfıra iterek örtük özellik seçimi yapar.
- L2 (Ridge): Katsayıların karelerinin toplamını ekler. Katsayıları küçültür ancak sıfırlamaz; çoklu doğrusal bağıntı durumunda katsayı kararlılığını artırır.
- Dropout: Sinir ağlarında, her eğitim adımında rastgele seçilen nöronları devre dışı bırakır. Bu, ağın tek bir yola bağımlı olmasını engeller.
- Erken Durdurma (Early Stopping): Doğrulama hatasını izleyerek artış eğilimi gözlendiğinde eğitimi sonlandırır.
Yöntem Seçimi Bağlamı
Küçük veri setlerinde ve çok sayıda özellik içeren problemlerde düzenleme neredeyse zorunludur. L1, özellik seçiminin önemli olduğu durumlarda; L2, tüm özelliklerin potansiyel olarak bilgilendirici olduğu durumlarda tercih edilebilir.
Kısa Kavrama Kontrolü
Yanıt
Eğitim ve test performansı arasındaki bu büyük fark (39 puanlık açık) klasik bir yüksek varyans / overfitting göstergesidir. Model, eğitim verisindeki gürültü dahil tüm yapıyı ezberlemiş ancak yeni veriye genelleyememektedir. Bias düşüktür (eğitim hatası düşük), varyans yüksektir (veri değiştiğinde tahminler dramatik biçimde bozulur). Hafifletme yaklaşımları: (1) Düzenleme: L2 (Ridge) katsayıları küçülterek modelin karmaşıklığını kısıtlar; L1 (Lasso) gereksiz özellikleri sıfırlayarak boyut azaltma sağlar; sinir ağlarında dropout uygulanabilir. (2) Erken durdurma: Doğrulama hatasını izleyerek artış başladığında eğitimi sonlandırma. (3) Daha fazla eğitim verisi: Mümkünse veri setini genişletmek, overfitting'in en doğrudan çözümüdür. (4) Model basitleştirme: Daha az parametre içeren bir model ailesi denemek (örn. derin ağ yerine sığ ağ veya doğrusal model). (5) Özellik seçimi veya boyut azaltma: Gereksiz veya gürültülü özellikleri çıkarmak. Bu yaklaşımlardan hangisinin etkili olacağı, sorunun kaynağına (aşırı parametre, yetersiz veri, gürültülü özellikler) bağlıdır.
6. Optimizasyon
6.1 Gradyan İniş (Gradient Descent)
Tanım
Kayıp fonksiyonunu minimize etmek için parametreleri, kaybın gradyanının tersi yönünde iteratif olarak güncelleyen optimizasyon algoritmasıdır: w ← w − η · ∇L(w), burada η öğrenme oranıdır.
Neden Gerekli?
Çoğu makine öğrenmesi modelinde parametrelerin analitik çözümü bulunmaz veya hesaplama açısından pratik değildir. Gradyan iniş, genel amaçlı ve ölçeklenebilir bir optimizasyon çerçevesi sağlar.
6.2 Öğrenme Oranı (Learning Rate)
Tanım
Her güncelleme adımının büyüklüğünü belirleyen hiperparametredir.
- Çok yüksek değer: kayıp fonksiyonu minimum etrafında salınabilir veya ıraksayabilir.
- Çok düşük değer: yakınsama aşırı yavaşlar; yerel minimumlara takılma riski artar.
Uygulamada genellikle 10-3–10-2 aralığında başlangıç değeri denenir ve öğrenme oranı zamanlama (scheduling) stratejileriyle dinamik olarak ayarlanır.
6.3 Yaygın Optimizasyon Algoritmaları
| Algoritma | Temel Fikir | Yaygın Kullanım Bağlamı |
|---|---|---|
| SGD | Her iterasyonda rastgele bir mini-batch üzerinden gradyan hesabı | Büyük veri setleri, konveks veya yaklaşık konveks problemler |
| Adam | Momentum ve parametre bazında adaptif öğrenme oranı birleşimi | Genel amaçlı ilk tercih; derin öğrenme uygulamalarında yaygın |
| RMSprop | Gradyan geçmişine dayalı adaptif öğrenme oranı | Yinelemeli sinir ağları ve durağan olmayan gradyan yapıları |
6.4 Hiperparametre Ayarlama
Tanım
Hiperparametreler, model eğitimi sırasında veriden öğrenilmeyen, kullanıcı tarafından belirlenen ayarlardır (örn. ağaç derinliği, öğrenme oranı, düzenleme katsayısı).
Arama Stratejileri
- Grid Search: Belirlenmiş değer kombinasyonlarını kapsamlı biçimde dener. Sistematik ama hesaplama maliyeti yüksek.
- Random Search: Rastgele kombinasyonlar dener. Genellikle grid search ile karşılaştırılabilir sonuçları daha az hesaplamayla üretir.
- Bayesian Optimization: Önceki denemelerden bilgi edinerek bir sonraki deneme noktasını seçer. Değerlendirme maliyetinin yüksek olduğu durumlarda verimlidir.
Kısa Kavrama Kontrolü
Yanıt
Bu davranış kalıbı genellikle öğrenme oranının aşırı yüksek olduğuna işaret eder. İlk epoch'larda kayıp düşer çünkü parametreler başlangıç noktasından minimum yönüne hareket eder. Ancak minimum civarına yaklaşıldığında, güncelleme adımları minimumu "atlayacak" kadar büyük olduğundan parametreler minimumun iki tarafı arasında salınır — kayıp düşmek yerine yukarı-aşağı dalgalanır. İlk denenmesi gereken müdahale: Öğrenme oranını azaltmak (tipik olarak 2–10 kat). Bu, adım büyüklüğünü küçülterek minimuma daha hassas yakınsamayı sağlar. Ek yaklaşımlar: (1) Öğrenme oranı zamanlama (scheduling) stratejisi uygulamak — örneğin başlangıçta yüksek, eğitim ilerledikçe kademeli azalan bir oran. (2) Adam gibi adaptif optimizer'lara geçmek — parametre bazında öğrenme oranını otomatik ayarladıklarından sabit orana göre salınıma daha dirençli olabilirler. (3) Gradient clipping uygulamak — gradyanların belirli bir eşiği aşmasını engelleyerek büyük güncelleme adımlarını sınırlar.
7. Sinir Ağlarına Giriş
7.1 Perceptron ve Çok Katmanlı Ağlar (MLP)
Tanım
Perceptron: Tek nöronlu yapı; girdileri ağırlıklarla çarpar, toplar ve bir aktivasyon fonksiyonundan geçirir. Yalnızca doğrusal olarak ayrılabilir problemleri çözebilir.
Çok Katmanlı Algılayıcı (MLP): Bir veya daha fazla gizli katman eklenerek oluşturulur. Gizli katmanlar, doğrusal olmayan ilişkilerin öğrenilmesine olanak tanır. Evrensel yaklaşım teoremi (universal approximation theorem), yeterli genişlikteki tek gizli katmanlı bir ağın herhangi bir sürekli fonksiyonu yaklaşıklayabileceğini belirtir; ancak bu, pratikte böyle bir ağın verimli biçimde eğitilebileceğini garanti etmez.
7.2 Aktivasyon Fonksiyonları
Tanım
Nöronun çıktısına doğrusal olmayanlık katan fonksiyonlardır. Aktivasyon fonksiyonu olmadan, katman sayısından bağımsız olarak ağın tamamı doğrusal bir dönüşüme indirgenir.
| Fonksiyon | İfade | Yaygın Kullanım |
|---|---|---|
| ReLU | max(0, x) | Gizli katmanlarda varsayılan tercih |
| Sigmoid | 1/(1+e-x) | İkili sınıflandırma çıkış katmanı |
| Softmax | Her sınıfa normalize olasılık atar | Çok sınıflı sınıflandırma çıkış katmanı |
| Tanh | (ex−e-x)/(ex+e-x) | Çıktının sıfır merkezli olması istenen durumlar |
7.3 Geri Yayılım (Backpropagation)
Tanım
Zincir kuralı (chain rule) aracılığıyla kayıp fonksiyonunun her parametre için kısmi türevini, çıkış katmanından girdi katmanına doğru geriye hesaplayan algoritmadır. Hesaplanan gradyanlar, gradyan iniş ile parametre güncellemesi için kullanılır.
7.4 Temel Mimari Aileleri
| Mimari | Temel Yapı | Uygun Veri Türü |
|---|---|---|
| CNN (Evrişimli Sinir Ağı) | Evrişim katmanları ile uzamsal hiyerarşi öğrenimi | Görüntü, uzamsal yapılı veri |
| RNN / LSTM | Yinelemeli bağlantılar ile ardışık bağımlılık öğrenimi | Zaman serileri, sıralı veri |
| Transformer | Öz-dikkat (self-attention) mekanizması ile paralel işleme | Metin, çok bantlı görüntü, çok değişkenli zaman serisi |
Sınırlar / Hatalı Kullanımlar
- Küçük veri setlerinde (tipik olarak birkaç yüz gözlem) derin modeller overfit etme eğilimi gösterir; bu koşullarda klasik yöntemler daha uygun olabilir.
- Yorumlanabilirlik gereksinimleri yüksekse, sinir ağlarının kara kutu yapısı ek açıklama araçları (SHAP, Grad-CAM vb.) gerektirir.
- Hesaplama kaynağı (GPU/TPU) gereksinimi, özellikle derin mimarilerde önemli bir pratik kısıttır.
Kısa Kavrama Kontrolü
Yanıt
Bu senaryoda rastgele ormanın tercih edilmesini destekleyen birkaç gerekçe vardır: (1) Veri boyutu: 500 gözlem, çok katmanlı derin bir ağın parametrelerini güvenilir biçimde öğrenmesi için yetersizdir. Derin modeller yüksek parametre kapasitesine sahiptir ve küçük veri setlerinde aşırı öğrenme riski çok yüksektir. Rastgele orman, bagging mekanizması sayesinde küçük-orta ölçekli verilerde daha kararlı genelleme üretir. (2) Özellik sayısı: 10 özellik, görece düşük boyutlu bir uzaydır. Derin öğrenmenin temel avantajlarından biri otomatik özellik çıkarımıdır — bu, ham piksel veya ham sinyal gibi yüksek boyutlu yapılandırılmamış verilerde kritiktir. Tablolu ve düşük boyutlu veride bu avantaj büyük ölçüde ortadan kalkar. (3) Yorumlanabilirlik: Rastgele orman, özellik önemi çıktısı sayesinde hangi değişkenlerin tahmine görece daha fazla katkıda bulunduğuna dair keşifsel bilgi sağlar. Derin ağlar ek açıklama araçları (SHAP, LIME) olmadan bu bilgiyi doğrudan sunmaz. (4) Hesaplama ve ayarlama maliyeti: Rastgele orman, hiperparametre seçimine karşı görece dirençlidir ve GPU gerektirmez. Derin ağlar ise mimari tasarım, öğrenme oranı, batch boyutu, epoch sayısı gibi çok sayıda hiperparametre kararı gerektirir.
8. Boyut Azaltma
8.1 PCA (Temel Bileşen Analizi)
Tanım
Yüksek boyutlu veriyi, varyansı en çok açıklayan doğrusal bileşenlere projekte eden bir dönüşümdür. Kovaryans matrisinin özvektörleri hesaplanır; ilk k özvektör, toplam varyansın büyük bölümünü açıklayan yeni eksenler tanımlar.
Neden Gerekli?
Özellik sayısı fazla olduğunda boyut azaltma, hesaplama maliyetini düşürür, overfitting riskini azaltır ve görselleştirme imkanı sağlar. Ayrıca çoklu doğrusal bağıntı taşıyan özellik setlerinde korelasyonu ortadan kaldırır.
Tarımsal Bağlamda Yeri
Tipik uygulama bağlamı: Hiperspektral uzaktan algılama verisinde yüzlerce spektral bant bulunabilir. PCA ile bu bantlar az sayıda bileşene indirgenerek modele girdi boyutu kontrol altına alınabilir. Bileşen sayısı seçiminde açıklanan varyans oranı incelenmelidir.
8.2 t-SNE ve UMAP
Tanım
Yüksek boyutlu veriyi 2D veya 3D uzayda görselleştirmek için kullanılan doğrusal olmayan boyut azaltma yöntemleridir. Temel amaçları, yerel komşuluk yapılarını koruyarak küme yapılarını görsel olarak keşfetmektir.
Sınırlar / Hatalı Kullanımlar
- Projeksiyondaki mesafeler nicel olarak yorumlanamaz; yalnızca nitel küme yapısı gözlemi için uygundur.
- Hiperparametre seçimi (perplexity, n_neighbors) sonucu önemli ölçüde etkiler; farklı ayarlarla tekrar edilmelidir.
- Bu yöntemler keşifsel görselleştirme araçlarıdır; analitik sonuç çıkarmak için kullanılmamalıdır.
9. Pratik Konular
9.1 ML İş Akışı (Pipeline)
Tanım
Tipik bir makine öğrenmesi projesinin aşamaları:
- Problem tanımlama: Tahmin hedefi ve başarı kriterinin belirlenmesi.
- Veri toplama: Mevcut veri kaynaklarının değerlendirilmesi, ek veri ihtiyacının tespiti.
- Keşifsel veri analizi (EDA): Dağılımlar, eksik değerler, korelasyonlar, aykırı gözlemler.
- Ön işleme ve özellik mühendisliği: Veriyi modele uygun biçime getirme.
- Model seçimi ve eğitim: Birden fazla aday modelin denenmesi.
- Değerlendirme: Test seti veya çapraz doğrulama ile performans ölçümü.
- Dağıtım (Deployment): Modelin üretim ortamına aktarılması.
- İzleme ve bakım: Veri kayması (data drift) ve performans bozulmasının düzenli kontrolü.
9.2 Model Seçimi
Tanım
No Free Lunch teoremi, tüm problemlerde üstün olan tek bir algoritmanın bulunmadığını ifade eder. Model seçimi, problem yapısına, veri özelliklerine, yorumlanabilirlik gereksinimlerine ve hesaplama kaynaklarına bağlı çok boyutlu bir karardır.
Genel yaklaşım: Basit bir baseline model ile başlayıp, karmaşıklığı performans kazanımı gerekçelendirdiği ölçüde artırmak yaygın bir stratejidir.
9.3 Dengesiz Veri Problemi
Tanım
Sınıf dağılımlarının belirgin biçimde eşit olmadığı durumlardır. Model, çoğunluk sınıfına doğru sapma gösterme eğilimindedir.
Yaygın Müdahale Yöntemleri
- Oversampling (SMOTE vb.): Azınlık sınıfından sentetik örnekler üretme.
- Undersampling: Çoğunluk sınıfının örneklem boyutunu azaltma.
- Sınıf ağırlıklandırma: Kayıp fonksiyonunda azınlık sınıfına daha yüksek ağırlık atama.
- Metrik seçimi: Doğruluk yerine F1, Recall veya PR-AUC kullanma.
Sınırlar / Hatalı Kullanımlar
SMOTE, yüksek boyutlu veya çok seyrek özellik uzaylarında sentetik örneklerin anlamlılığı tartışmalı olabilir. Dengesizlik müdahalesinin etkisi problem bağlamında değerlendirilmeli, otomatik olarak uygulanmamalıdır.
9.4 Açıklanabilir Yapay Zeka (XAI)
Tanım
Modelin tahmin gerekçelerini anlaşılabilir kılmaya yönelik yöntemlerdir.
- SHAP (SHapley Additive exPlanations): Oyun teorisi temelli; her özelliğin bireysel tahmine marjinal katkısını ölçer.
- LIME (Local Interpretable Model-agnostic Explanations): Tek bir tahminin çevresinde yorumlanabilir yerel bir model kurarak açıklama üretir.
- Özellik önemi (Feature Importance): Ağaç tabanlı modellerde, her özelliğin bölünme kararlarına olan katkısının toplamı.
Tarımsal Bağlamda Yeri
Tarımsal karar destek sistemlerinde açıklanabilirlik, teknik bir gereklilik olmanın ötesinde, son kullanıcı güveni ve benimsenmesi açısından kritik bir faktördür. Açıklama üretemeyen bir model, teknik olarak başarılı olsa dahi, saha uygulamasında benimsenme güçlüğü yaşayabilir.
Kısa Kavrama Kontrolü
Yanıt
Model değişmediğine göre sorun modelde değil, modelin karşılaştığı veridedir. Bu durumun temel kaynağı veri kayması (data drift)dır — üretim ortamındaki verinin istatistiksel dağılımının, modelin eğitildiği verinin dağılımından farklılaşmasıdır. Olası kaynaklar: (1) Kovaryat kayması (covariate shift): Girdi değişkenlerinin dağılımı değişmiştir. Örneğin model belirli bir iklim döneminin verisiyle eğitildiyse, farklı mevsimsel koşullar veya olağandışı bir kurak/yağışlı dönem girdi dağılımını kaydırabilir. (2) Konsept kayması (concept drift): Girdi-çıktı ilişkisinin kendisi değişmiştir. Yeni bir çeşidin ekime girmesi, sulama altyapısının değişmesi veya yeni bir hastalık etkeninin ortaya çıkması, aynı girdi koşullarında farklı çıktılar üretilmesine yol açabilir. (3) Veri toplama sürecindeki değişiklikler: Sensör kalibrasyonunun kayması, farklı bir uydu platformuna geçiş veya ölçüm protokolündeki değişiklikler, verinin biçimini modelin beklentisinden saptırabilir. Çözüm yaklaşımı: Üretim verisinin dağılımını periyodik olarak izlemek (drift detection), performans düşüşü tespit edildiğinde modeli güncel veriyle yeniden eğitmek veya ince ayar yapmak (retraining/fine-tuning) ve dağıtım sonrası izleme (monitoring) pipeline'ını sistematik biçimde kurmaktır.
A. Bütünleştirici Özet
Makine öğrenmesi iş akışı, birbirine bağlı aşamalardan oluşan bir zincirdir. Her aşamadaki hata, sonraki adımlara taşınır.
Veri tüm sürecin temelini oluşturur. Veri türleri uygun ön işleme adımlarını belirler: ölçekleme, eksik veri işleme ve kodlama. Bu adımların doğruluğu, veri sızıntısı olmaksızın yalnızca eğitim setinden türetilen parametrelere dayanmasını gerektirir.
Paradigma seçimi problemin yapısına ve etiketli veri durumuna bağlıdır. Etiketli veri mevcutsa denetimli öğrenme; yoksa denetimsiz keşif; az etiket varsa yarı-denetimli; ardışık karar yapısı varsa pekiştirmeli öğrenme değerlendirilir.
Algoritma seçimi tek doğru cevabı olan bir karar değildir. Basit bir baseline ile başlayıp, karmaşıklığı performans kazanımı gerekçelendirdiği ölçüde artırmak sağlam bir stratejidir. Her algoritmanın güçlü yönleri ve varsayımları vardır; bunlar problem bağlamıyla eşleştirilmelidir.
Değerlendirme tek bir metriğe indirgenemez. Sınıf dağılımı, hata türlerinin maliyeti ve verinin zamansal/mekânsal yapısı, uygun metrik ve doğrulama stratejisini belirler. Eğitim performansı raporlamak yanıltıcıdır; test veya çapraz doğrulama performansı esas alınmalıdır.
Overfitting en yaygın başarısızlık biçimidir. Düzenleme teknikleri (L1, L2, dropout, erken durdurma) ve yeterli doğrulama stratejileri ile kontrol altına alınabilir.
Dağıtım sonrası izleme genellikle ihmal edilen ancak kritik bir aşamadır. Veri kayması (data drift) — eğitim verisinin dağılımı ile üretim ortamı verisinin dağılımı arasındaki farklılaşma — zamanla model performansını düşürebilir.
B. Sınıfta Anlatım Notu
Eğitmenin Vurgulaması Gereken 5 Kritik Nokta
- Veri kalitesi, model seçiminden önce gelir. Algoritma değiştirmek yerine veri kalitesini artırmak çoğu zaman daha büyük performans kazanımı sağlar.
- Test setine eğitim sırasında bakılmaz. Veri sızıntısı kavramı öğrencilerin en sık yaptığı ve en geç fark ettiği hata türüdür.
- Doğruluk (accuracy) her zaman yeterli bir metrik değildir. Dengesiz sınıf yapısında sabit tahmin stratejisi ile yüksek doğruluk elde edilebileceği somut olarak gösterilmelidir.
- Eğitim performansı değil, test/doğrulama performansı raporlanır. Eğitim hatası düşük, test hatası yüksekse overfitting; her ikisi de yüksekse underfitting.
- Model, dağıtım sonrası statik değildir. Veri kayması kavramı ve periyodik yeniden değerlendirme gerekliliği baştan anlatılmalıdır.
Öğrencilerin En Sık Karıştıracağı 5 Nokta
- Lojistik regresyon ile doğrusal regresyon: Adlarındaki benzerlik nedeniyle karıştırılır; biri sınıflandırma, diğeri regresyon yöntemidir.
- Doğrulama seti ile test setinin işlevi: Doğrulama seti hiperparametre ayarında, test seti yalnızca nihai performans ölçümünde kullanılır. Rolleri birbirine karıştırılmamalıdır.
- Özellik önemi ile nedensellik: Ağaç tabanlı modellerin ürettiği özellik önemi değerleri korelasyon temelli çıkarımlardır; nedensel ilişki olarak yorumlanmamalıdır.
- Düzenleme ile özellik mühendisliği: Her ikisi de model performansını artırabilir, ancak farklı mekanizmalara sahiptir. Düzenleme mevcut özelliklerin katsayılarını kısıtlar; özellik mühendisliği yeni bilgi kanalları açar.
- Denetimsiz öğrenme "doğruluğu": Etiket olmadığında modelin "ne kadar doğru" olduğu denetimli paradigmadaki anlamıyla ölçülemez. Kümeleme kalitesi, iç tutarlılık metrikleri (silhouette, Davies-Bouldin) veya alan bilgisi ile değerlendirilir.
Sonraki Adım
Bu kavramsal çerçeveyi edindikten sonra 1.0 Tarımda Makine Öğrenmesi sayfasından uygulama alanlarına geçilebilir.